Dimension exploration
Dimension exploration gives users the ability to create alerts for every value of a certain dimension or combination of dimensions.
This is similar to running a for loop on different sets of values on the same detection workflow.
Problem description
Let’s take a look at the page views example. pageviews is a metric which computes the views aggregated by sum over a given time period. You can create an alert that fires if pageviews drops by 5% using a single alert.
However, what if the user wants to be alerted for a pageviews drop of 5% by country? The user would have to create a separate alert for each country.
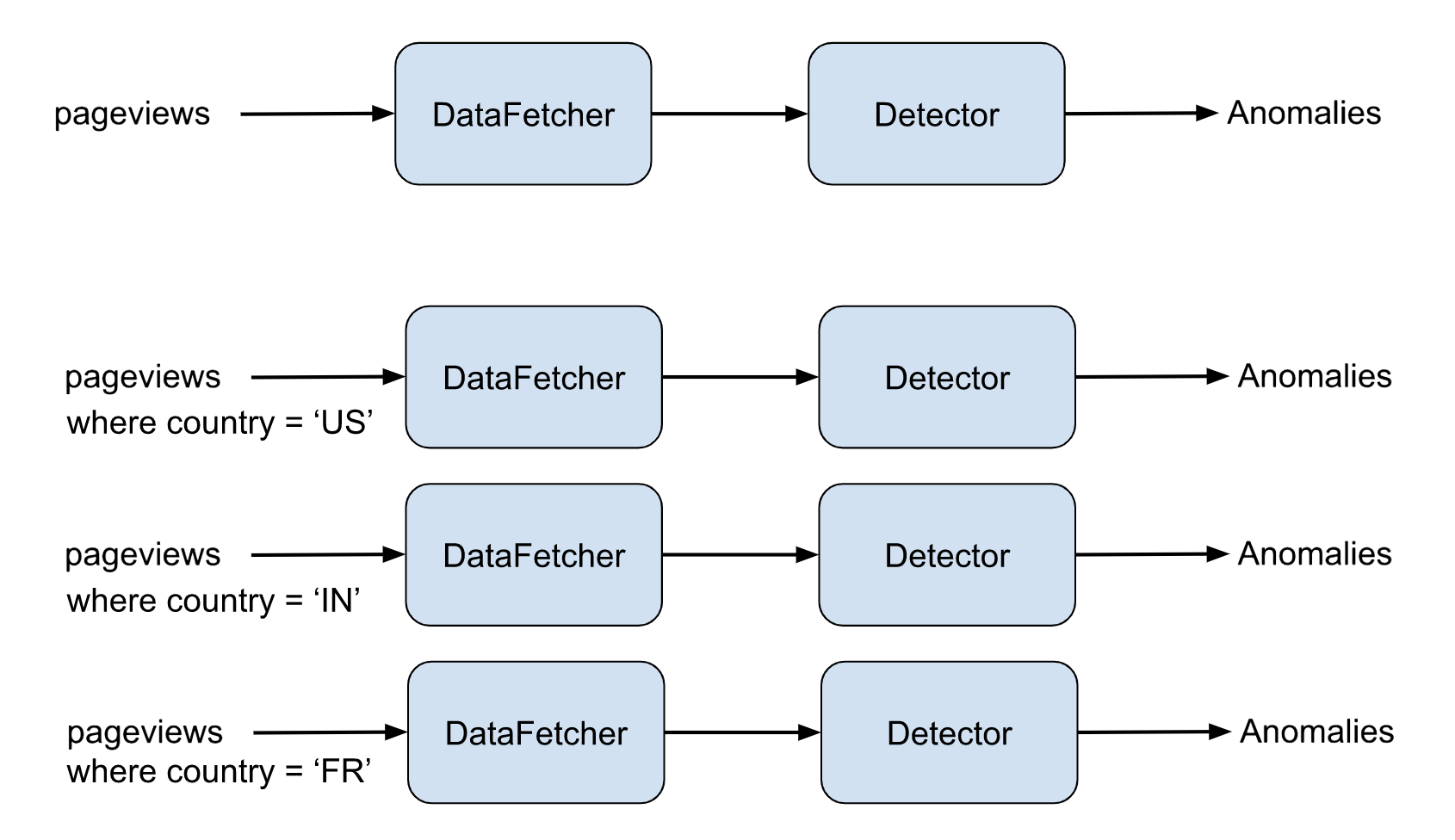
This is the problem that dimension exploration tries to solve by giving the user the ability to write a single alert to monitor a workflow for different values of dimensions, in this example, country = { ‘US’, ‘IN’, ‘FR’ }.
Approach
The approach here leverages the flexibility of the detection pipeline to be able to model a ‘loop’ within a workflow.
Detection pipeline DAG
The detection pipeline supports nodes that allow multiple named input and output streams. This section provides a simplified directed acyclic graph (DAG).
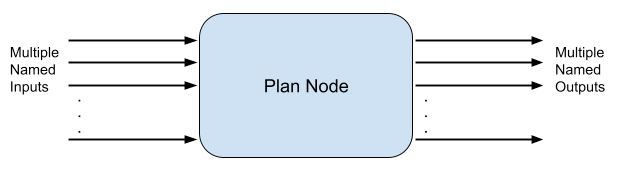
This gives us the ability to introduce 3 new primitives/operators.
- Enumerator Node
- Fork Join Node
- Combiner Node
Enumerator node
An enumerator node outputs a set of key-value pairs. These key-value pairs will be used to determine the template variables used for running the ‘loop’.
Output schema
List<Map<String, Object>>Each of the items in a list is a map containing template variables and values. Therefore, an enumerator can emit multiple variables and values per iteration.
Current template variables in ThirdEye are restricted to strings. This poses a design limitation since there is no way to feed structured data back into the template.
An enumerator itself can be of different types.
Dynamic dimensions using dataframe enumerator (Beta)
ThirdEye supports enumerating an alert based on the results of a query. The query can be any valid SQL query that returns a dataframe. The dataframe is then used to enumerate the alert.
Here is an example alert payload.
{
"name": "pageviews per country",
"description": "This is a sample detection",
"template": {
"name": "startree-threshold-query-dx"
},
"templateProperties": {
"dataSource": "pinot",
"dataset": "pageviews",
"monitoringGranularity": "P1D",
"aggregationColumn": "views",
"aggregationFunction": "sum",
"max": "900000",
"min": "100000",
"enumeratorQuery": "SELECT DISTINCT country FROM pageviews"
},
"cron": "0 */15 * * * ?"
}In this case, the enumeratorQuery parameter takes a SQL query that returns a dataframe.
Manual listing using default enumerator
The default enumerator node could be configured to emit a series of values configured as-is.
This allows the user to pass a set of template properties that can be fed into the child pipeline. In this example, different values of the queryFilter property will be fed into the pipeline for each run.
{
"name": "enumerator",
"type": "Enumerator",
"params": {
"type": "default",
"items": "${enumerationItems}"
}
}where enumerationItems is a template variable that can be fed in using a JSON like this
{
"name": "my alert",
... other properties,
"templateProperties": {
"dataSource": "pinot",
...
"enumerationItems": [
{
"name":"US Only",
"params": {
"queryFilters": " AND country = 'US'",
"max": 300000,
"min": 100000
}
},
{
"name": "Overall",
"params": {
"queryFilters": "",
"max": 900000,
"min": 300000
}
}
]
}
}Combiner node
The combiner node accepts the results of a fork operator and combines all the results.
A combiner can have different types. Initial approach would be to have a combiner that combines anomalies from each of the enumerations and tags them accordingly.
Example: The expectation here is to consume a list of outputs from each DAG and emit a single consolidated output. Note that each node can have multiple outputs. It is essentially flattening a set of lists into a single list.
{
"name": "combiner",
"type": "Combiner"
}In this case, we use the default combiner, which should work fine for most use cases.
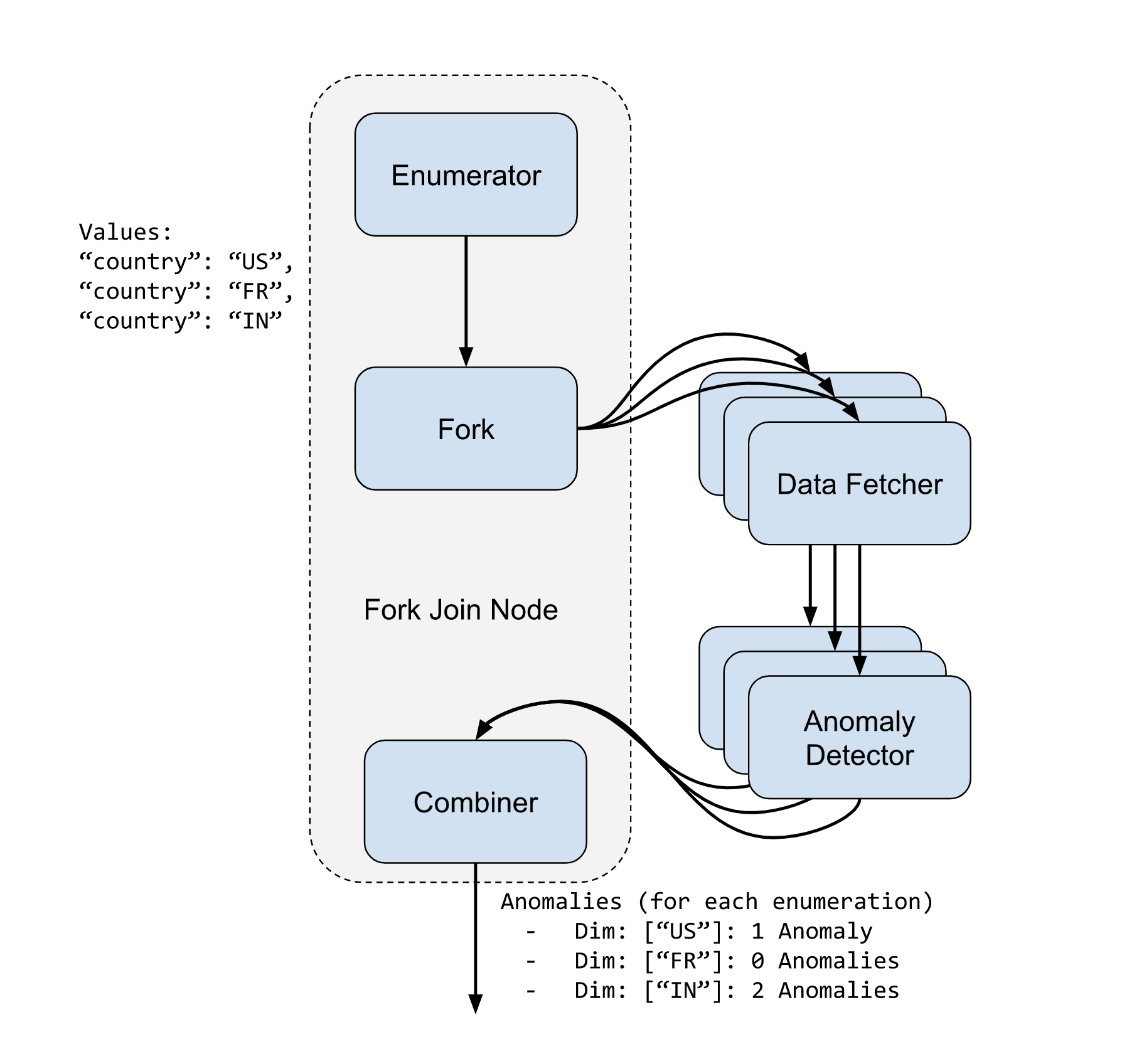
Fork join node
A fork join node follows a fork + join model which allows the user to input a set of enumerations. The fork join node forks the pipeline to execute a sub workflow DAG for each of the enumerations.
Operation
The Fork Join Node takes 3 parameters:
- Enumerator: This is an enumerator node that will be used to get all the enumerations that need to be executed
- Root: This is the root node of the sub DAG that the fork join is supposed to execute feeding in the enumerations
- Combiner: This is the combiner node that will consume the list of outputs from each enumeration execution.
The sub-DAG execution is done in parallel in a threaded execution model to leverage parallelization.
Each execution of the fork join consumes an entry from the enumerator. This is what we call an enumeration item.
Enumeration item
The enumeration node generates a list of enumeration items. These contain a set of parameters that are fed in the sub pipeline which is executed in the fork join. They define the results of the pipeline—meaning, any anomalies which may be calculated in the sub pipeline need to be attributed to the corresponding enumeration item.
For ease of access, filtering and other operations, enumeration items are also persisted in the database as entities. Here is a sample enumeration item entity
{
"name": "US, 1.0",
"description": "slice for US only results",
"params": {
"queryFilter": " AND country='US' AND version='1.0'"
}
}Anomalies generated with this pipeline is automatically tagged with the enumeration item:
{
// anomaly object
"id": 1234,
...
"enumerationItem": {
"id": 1234
}
}