ThirdEye worker management
ThirdEye consists of 3 components
- Coordinator : serves the APIs for UI
- Scheduler : schedules tasks for detection, onboarding, notification, etc
- Worker : carries out the execution of tasks scheduled by scheduler
As Worker does most of the heavy lifting in terms of computations and resource usage it becomes necessary to have the provision of adding more workers to the setup to distribute the task load. In this section we will discuss how ThirdEye handles the multiple workers and what strategy is in place to distribute the load across all these workers.
Overview
All the components interact with each other indirectly through the MySQL database. For example coordinator creates an alert based on the API call from UI. Scheduler iterates on this alert and creates a job that runs at fixed intervals defined by the cron in the alert. These job runs creates tasks in the database which are then picked by workers to execute.
When we introduce multiple workers we need to ensure that
- workers don't rerun a task which is already picked by another worker for execution
- workers don't overload the database with queries in order to get tasks
- load is evenly distributed among the workers
- each task is ran to completion and not left unpicked or stuck in bad state
Why we need this?
To make ThirdEye scalable, consistent and efficient the system needs to be fine-tuned to get the most out of given resources. Thirdeye worker management tries to address:
- Flexibility in vertically scaling an individual worker
- Even load distribution among multiple workers
- Minimal moving parts in the architecture to reduce maintenance and points of failure
- Disaster recovery during and after worker failures
- Ability to tune workers based on known load patterns
Architecture
Worker characteristics
- Each worker has a unique worker id
- The worker achieves parallelism internally using multi-threading
- Each worker builds an internal virtual queue which is used to pull tasks for execution
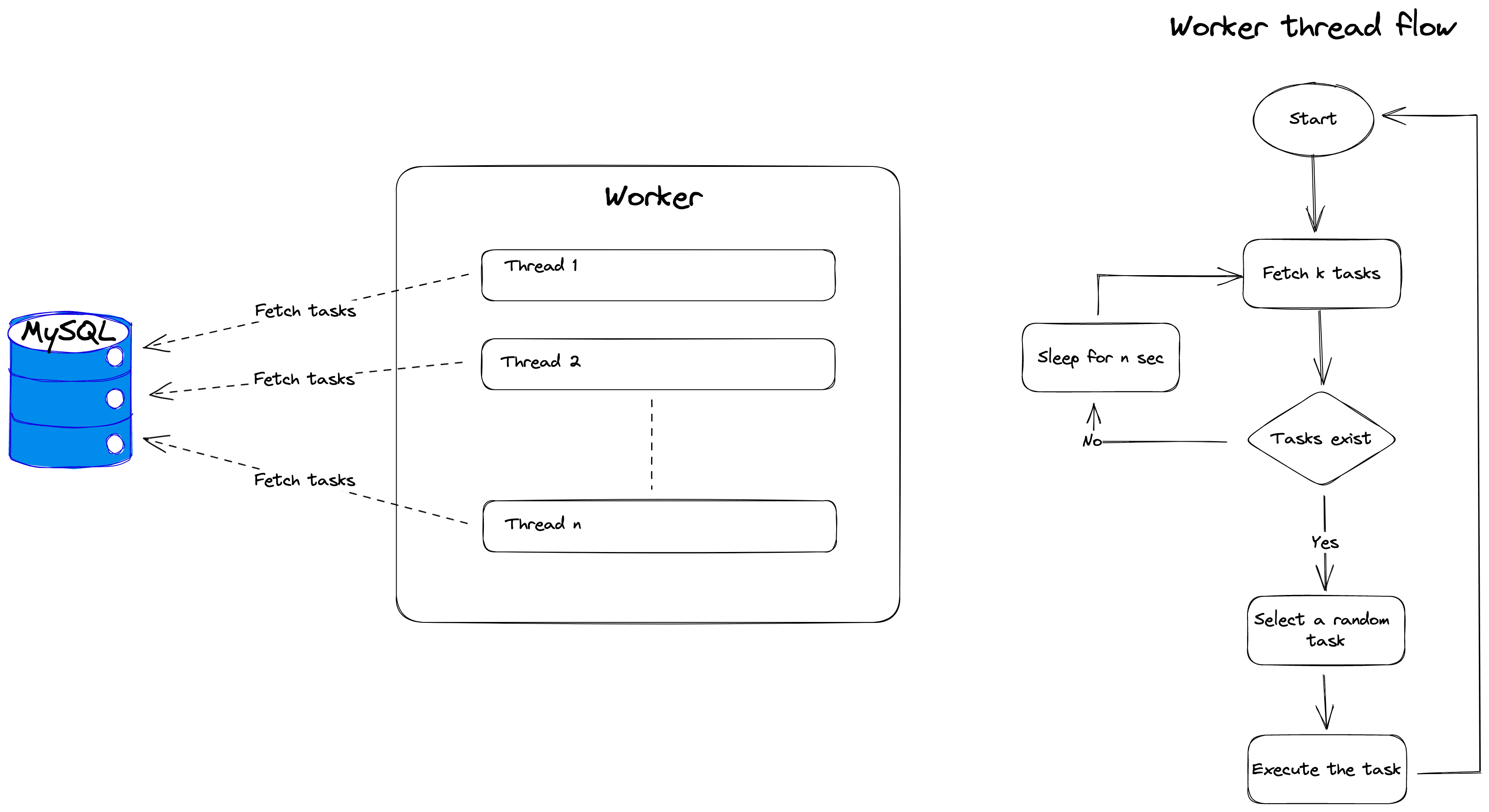
Different knobs are exposed as configurations to fine tune the worker characteristics based on the given use cases.
Configuring a worker
Achieve unique worker id
The configuration file (server.yaml) has a configuration
taskDriver:
id: <worker id>If the ThirdEye setup is deployed on bare metal VMs, we can simply provide unique ids to each worker instance through their configuration file.
But if the setup is deployed on a Kubernetes cluster using helm charts, we need to enable the
randomWorkerIdEnabled flag as the worker replicas will be identical and refer a common worker
configuration file.
taskDriver:
randomWorkerIdEnabled: trueThis can also be used in the bare metal setup
Reduce DB overhead
As each worker has parallel threads running internally, we need to set the parallelism based on the expected load on the worker. Overestimating the parallelism may lead to DB overhead as each thread will keep on querying the DB for tasks but won't get any as all the tasks would be picked up already.
taskDriver:
maxParallelTasks: <default is 5>Sometimes it may be possible that the task load is not evenly distributed over time. There may be tasks that runs hourly, daily, etc. In such cases we need the parallelism as there is a task load after each hour. In such cases we can increase the sleep time for a thread when the thread is not able to fetch a task
taskDriver:
noTaskDelay: <default is PT15S> # 15 seconds (ISO 8601 standard)We can set it to say PT15M (15 minutes) if we only have tasks being scheduled hourly.
Avoid worker collision
In multi-worker setup, it's possible that more than one worker picks up the same task simultaneously. Normally the conflict gets resolved based on which worker updates the task status first in the database, but ideally it's good to avoid this situation as this leads to unnecessary cpu cycles on worker and database queries on MySQL.
This can be achieved by
- increasing queue depth to accommodate more tasks -> reduce probability of collision
- increase the range of random delay so that workers are out of sync while fetching tasks from db
taskDriver:
taskFetchSizeCap: <default is 50>
randomDelayCap: <default is PT15S> # 15 seconds (ISO 8601 standard)