All About That Dough Pizza Shop
This demo app is a real-time analytics dashboard for the operators of All About That Dough (AATD), an online pizza delivery service that specalizes in pizzas with Indian toppings. They will use the dashboard to get a live view on the number of orders and revenue of their business and to keep an eye on the most popular products.
Demo
The gif below shows the Pizza Shop Dashboard:
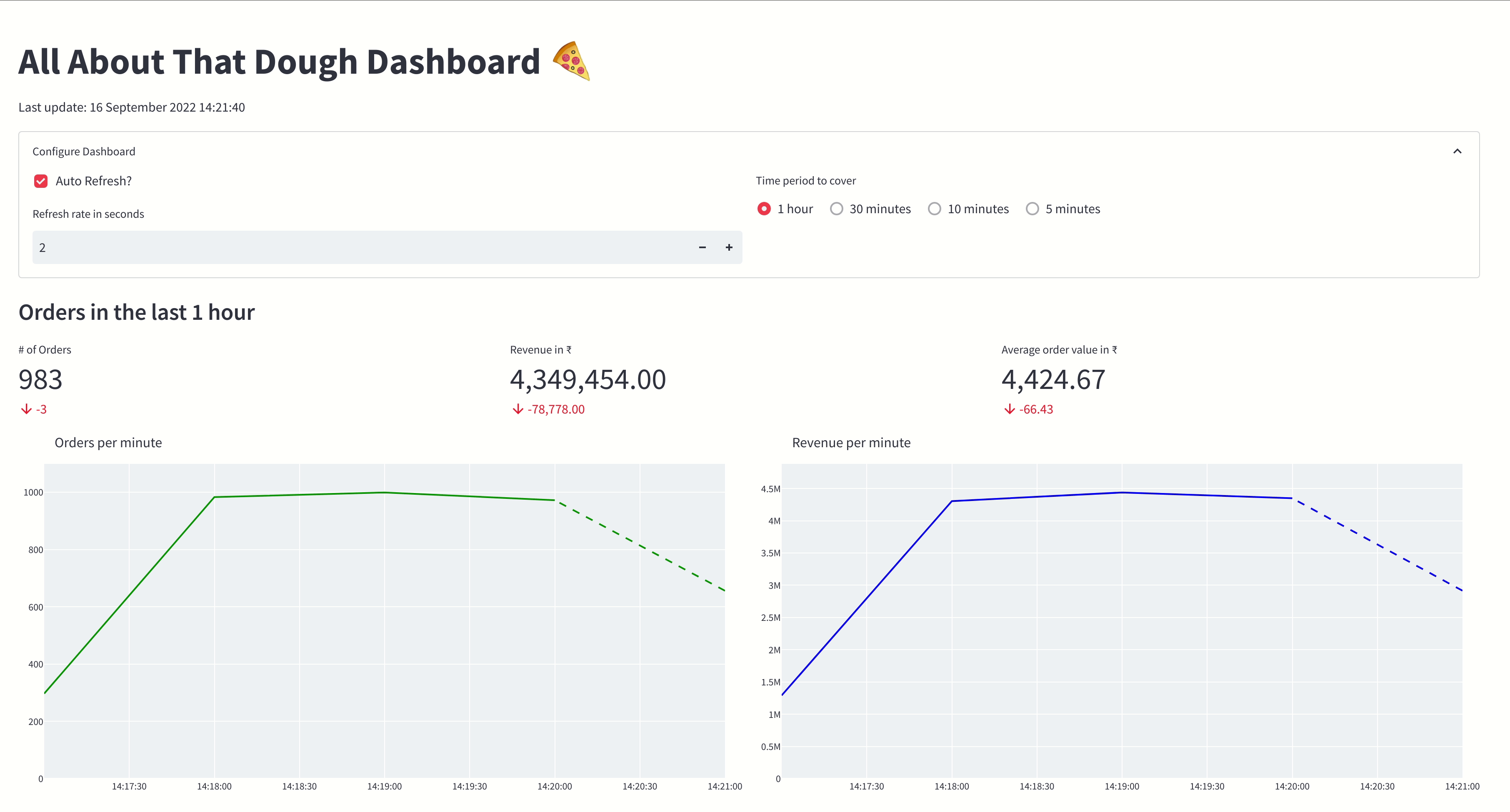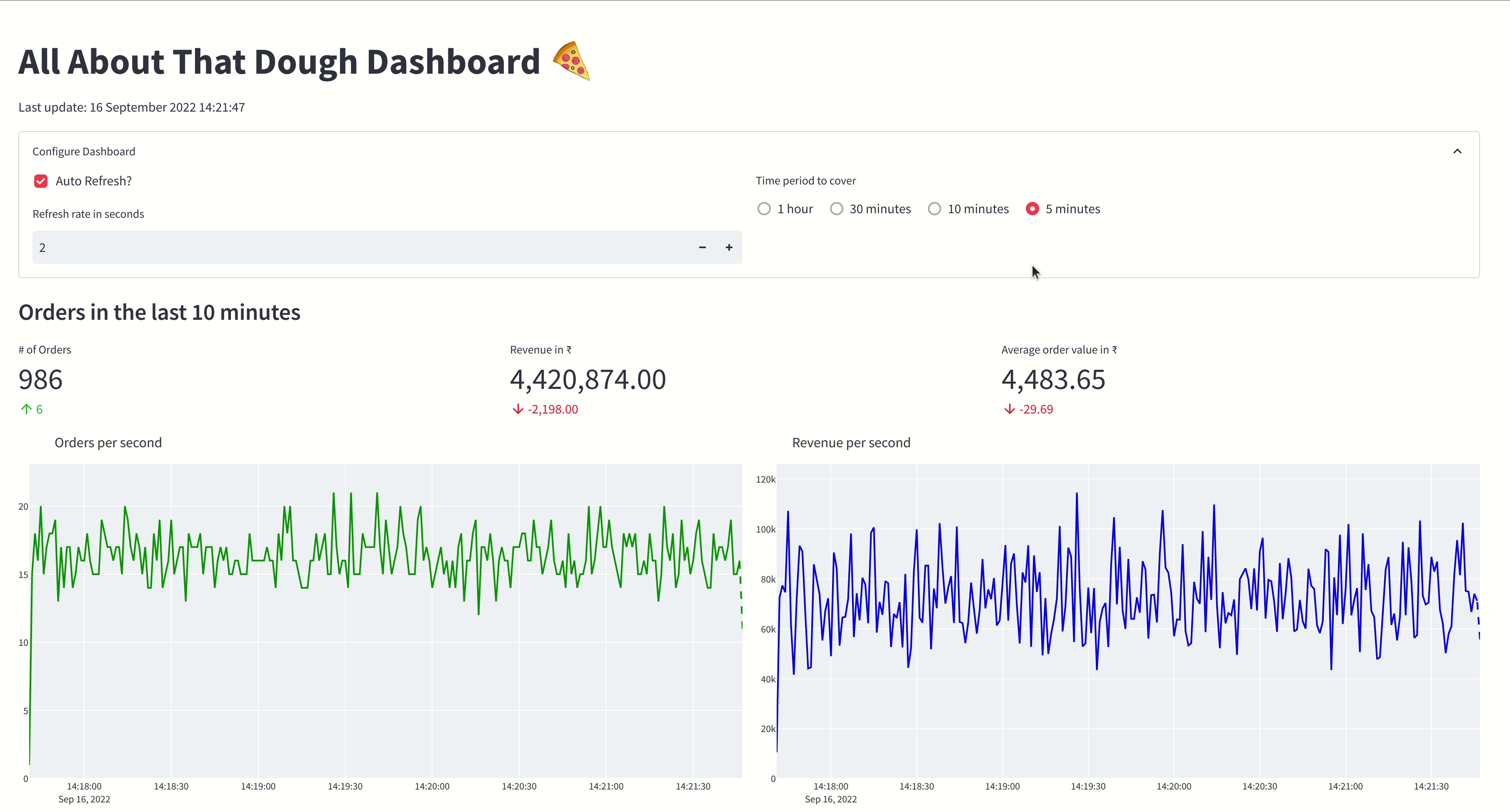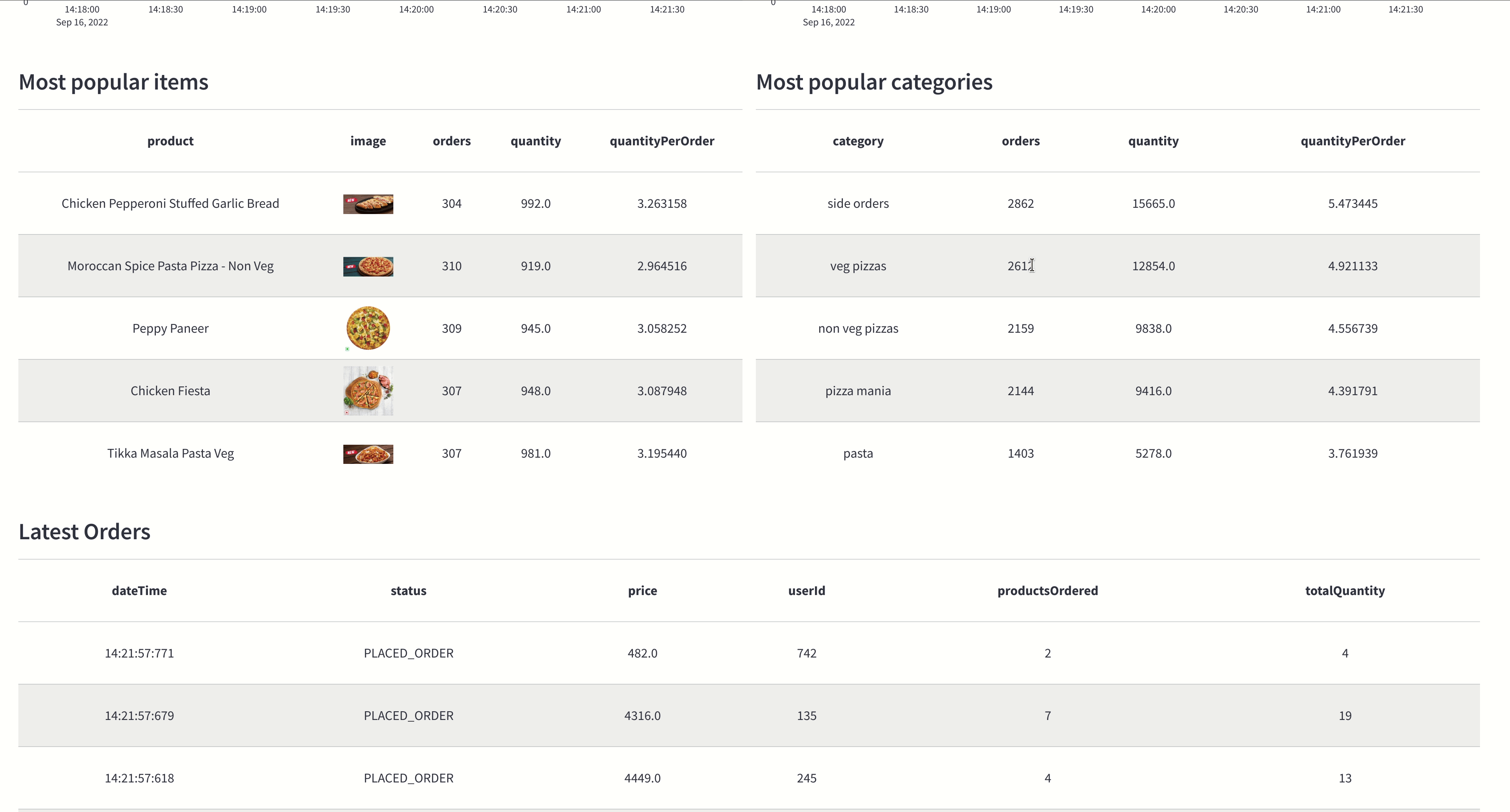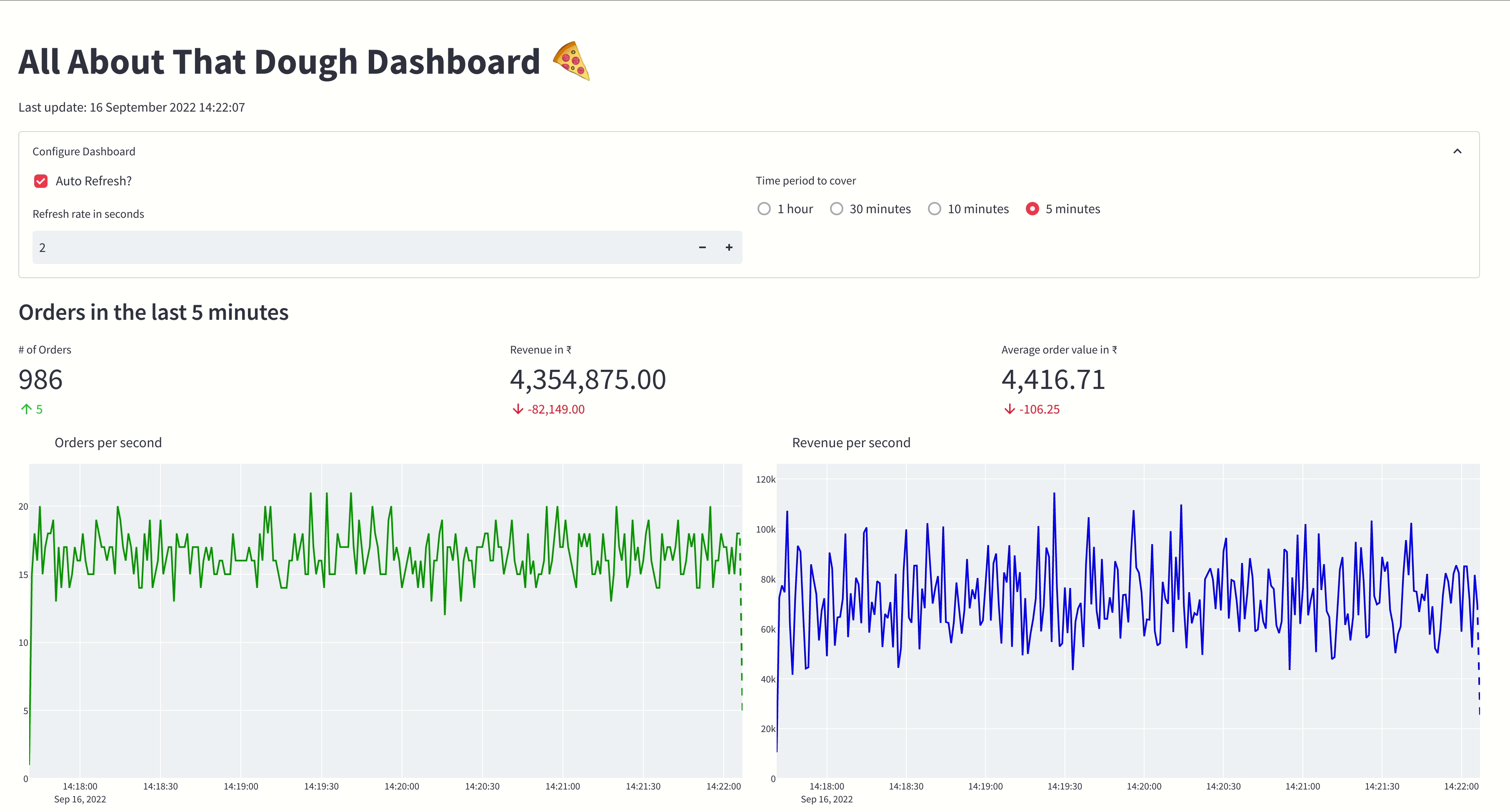
Installation
Clone the GitHub repository:
git clone git@github.com:startreedata/pizza-shop-demo.git
cd pizza-shop-demoLaunch all the components using Docker Compose:
docker-compose \
-f docker-compose-base.yml \
-f docker-compose-pinot.yml \
-f docker-compose-dashboard-enriched.yml \
upNavigate to localhost:8502 (opens in a new tab) to view the dashboard.
A deeper dive
In this section we'll go into detail about how data flows around the system.
Architecture Diagram
Below is an architecture diagram showing how all the compnents work together.
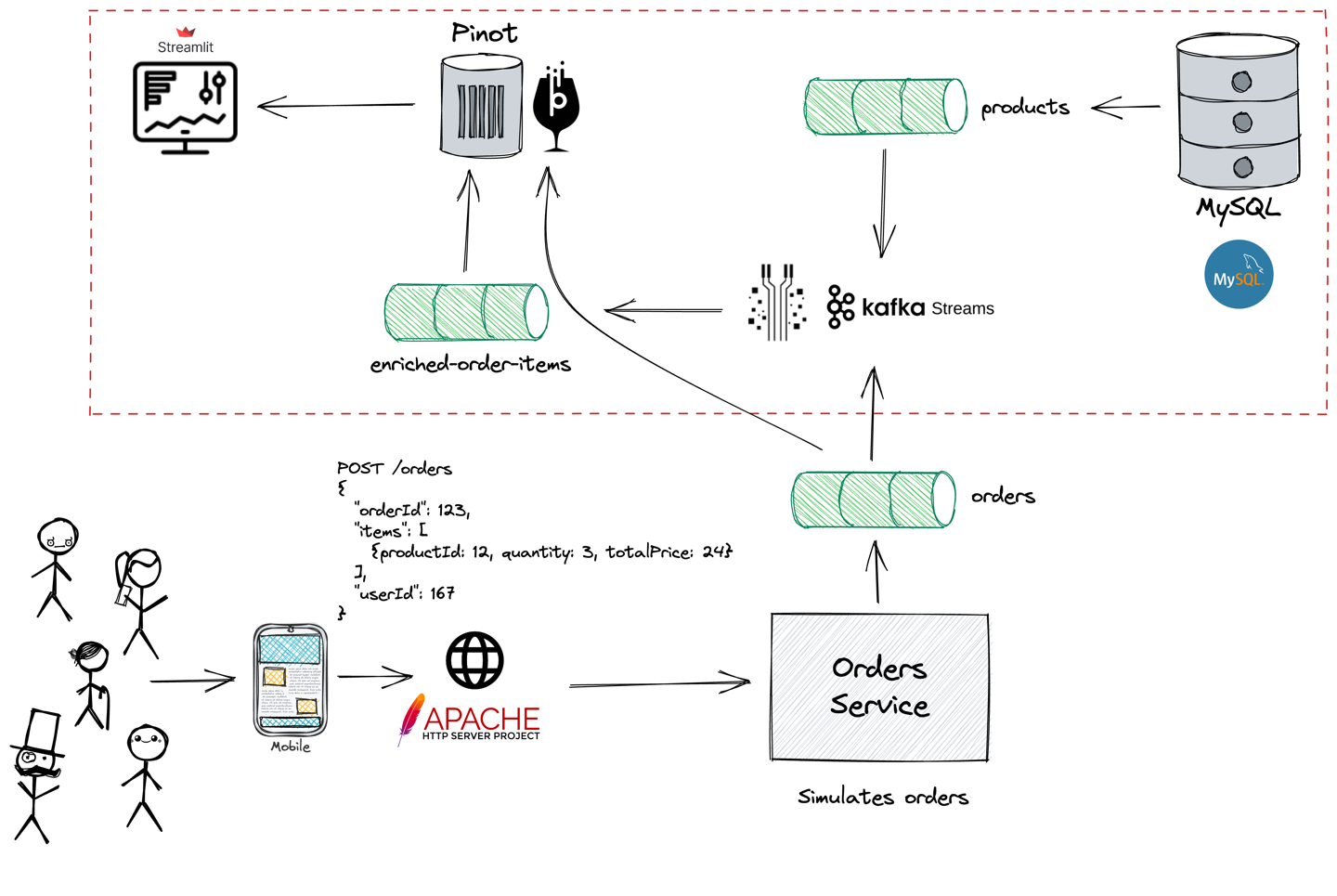
Data Entities
The orders service acts as the data generator in this demo app. It creates products and users that are published to MySQL and orders that are published to Apache Kafka.
Let's explore each of those entities.
Products
There are ~100 products, representing the types of items that you could buy from an online pizza delivery service. AATD sell pizzas, pasta, and a range of side orders.
You can query the catalog of products by first connecting to MySQL:
docker exec -it mysql mysql -u mysqluser -pThe password is mysqlpw.
You'll then see a prompt and you can paste the following query:
SELECT name, description, category, price
FROM pizzashop.products
LIMIT 10;Users
There are 1,000 users, generated using the Faker library. Users are also stored in MySQL and can be queried like this:
SELECT id, first_name, last_name, email, country
FROM pizzashop.users
LIMIT 10;Orders
There are an infinite number of orders, which comprise the products described above and are made by one of the users. You can query the orders stream, using the kcat (kafkacat on Linux) command line tool, like this:
kcat -C -b localhost:29092 -t orders -c 10or
kafkacat -C -b localhost:29092 -t orders -c 10An example order:
{
"id": "3d0d442f-1afc-494a-8c75-0e67fa8b31d4",
"createdAt": "2022-09-06T10:46:17.481843",
"userId": 521,
"status": "PLACED_ORDER",
"price": 1611,
"items": [
{
"productId": "43",
"quantity": 2,
"price": 609
},
{
"productId": "20",
"quantity": 3,
"price": 85
},
{
"productId": "14",
"quantity": 2,
"price": 569
}
]
}
Order Items
Order items are initially contained inside orders, but we use Kafka Streams to extract them and join them with product details, before publishing to the enriched-order-items stream.
kafkacat -C -b localhost:29092 -t enriched-order-items -c 10An example order item:
{
"orderId": "7bcd4bbe-c1a6-4bb3-807e-386a837bc2b3",
"createdAt": "2022-09-13T05:22:53.617952",
"product": {
"id": "3",
"name": "Pepsi Black Can",
"description": "PEPSI BLACK CAN",
"category": "beverages",
"image": "https://www.dominos.co.in//files/items/pepsi_black.png",
"price": 60
},
"orderItem": {
"productId": "3",
"quantity": 3,
"price": 60
}
}Apache Pinot
We store the data from the orders and enriched-order-items streams in Apache Pinot. Each stream has their own table and associated schema.
Orders
orders is a real-time table that consumes data from the orders stream.
The schema is defined below:
{
"schemaName": "orders",
"dimensionFieldSpecs": [
{"name": "id", "dataType": "STRING"},
{"name": "userId", "dataType": "INT"},
{"name": "status", "dataType": "STRING"},
{"name": "items", "dataType": "JSON"}
],
"metricFieldSpecs": [
{"name": "productsOrdered", "dataType": "INT"},
{"name": "totalQuantity", "dataType": "INT"},
{"name": "price", "dataType": "DOUBLE"}
],
"dateTimeFieldSpecs": [
{
"name": "ts",
"dataType": "TIMESTAMP",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}And the table config:
{
"tableName": "orders",
"tableType": "REALTIME",
"segmentsConfig": {
"schemaName": "orders",
"timeColumnName": "ts",
"timeType": "MILLISECONDS",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowLevel",
"stream.kafka.topic.name": "orders",
"stream.kafka.decoder.class.name":
"org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name":
"org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "kafka:9092",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"ingestionConfig": {
"transformConfigs": [
{
"columnName": "ts",
"transformFunction": "FromDateTime(createdAt, 'yyyy-MM-dd''T''HH:mm:ss.SSSSSS')"
}
]
},
"metadata": {"customConfigs": {}},
"routing": {"instanceSelectorType": "strictReplicaGroup"}
}Order Items Enriched
order_items_enriched is a real time table that consumes data from the enriched-order-items stream.
The schema is defined below:
{
"schemaName": "order_items_enriched",
"dimensionFieldSpecs": [
{"name": "orderId", "dataType": "STRING"},
{"name": "product.id", "dataType": "STRING"},
{"name": "product.name", "dataType": "STRING"},
{"name": "product.category", "dataType": "STRING"},
{"name": "product.image", "dataType": "STRING"}
],
"metricFieldSpecs": [
{"name": "product.price", "dataType": "DOUBLE"},
{"name": "orderItem.quantity", "dataType": "INT"}
],
"dateTimeFieldSpecs": [
{
"name": "ts",
"dataType": "TIMESTAMP",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}And the table config:
{
"tableName": "order_items_enriched",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "ts",
"timeType": "MILLISECONDS",
"schemaName": "order_items_enriched",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowLevel",
"stream.kafka.topic.name": "enriched-order-items",
"stream.kafka.decoder.class.name":
"org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name":
"org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "kafka:9092",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"ingestionConfig": {
"transformConfigs": [
{
"columnName": "ts",
"transformFunction": "FromDateTime(\"createdAt\", 'yyyy-MM-dd''T''HH:mm:ss.SSSSSS')"
}
]
},
"metadata": {"customConfigs": {}},
"routing": {"instanceSelectorType": "strictReplicaGroup"}
}Dashboard
The code for the dashboard is written using Streamlit, a Python based framework for building interactive web applications. We query Pinot using its Python client and render results using Pandas' DataFrames and plot.ly charts.