Ingest Parquet files from an S3 Bucket into Pinot Using Spark
In this recipe we'll learn how to ingest Parquet formatted data from an AWS S3 bucket into a Pinot cluster. The ingestion will be executed as an Apache Spark job. Once the data is ingested, we will run ad hoc queries against Pinot to derive valuable insights with the lowest latency.
These are the plugins we will be using throughout the tutorial:
- pinot-batch-ingestion-spark
- pinot-s3
- pinot-parquet
| Pinot Version | 0.9.3 |
| Code | startreedata/pinot-recipes/ingest-parquet-files-from-s3-using-spark |
Prerequisites
This tutorial requires you have these on your local workstation.
- JDK version 11 or higher
- Apache Spark 2.4.8 with Hadoop 2.7 (opens in a new tab)
- Apache Pinot 0.9.3 binary distribution (opens in a new tab)
- An AWS S3 (opens in a new tab) account with reading and write permissions
- AWS CLI (opens in a new tab) installation with properly configured access key credentials (opens in a new tab).
Overview
To understand how these plugins work together, let’s take an example of a fictitious mobile application.
The company Foo recently launched a mobile application. Now, the engineering team is curious to learn the user engagement statistics of the application. They are planning to calculate the daily active users (DAU) metrics to quantify that information.
The mobile app emits an event similar to this whenever a user performs an activity in the application.
{
"eventId":"950ce51e-2f14-406a-a17f-27279f181ef3",
"userId":1234,
"eventType":"Comment",
"ts":1633114228000
}These events are sent to the backend and subsequently accumulated into an S3 bucket in Parquet format. Our goal is to ingest those events into Pinot and then write a SQL query to calculate the DAU.
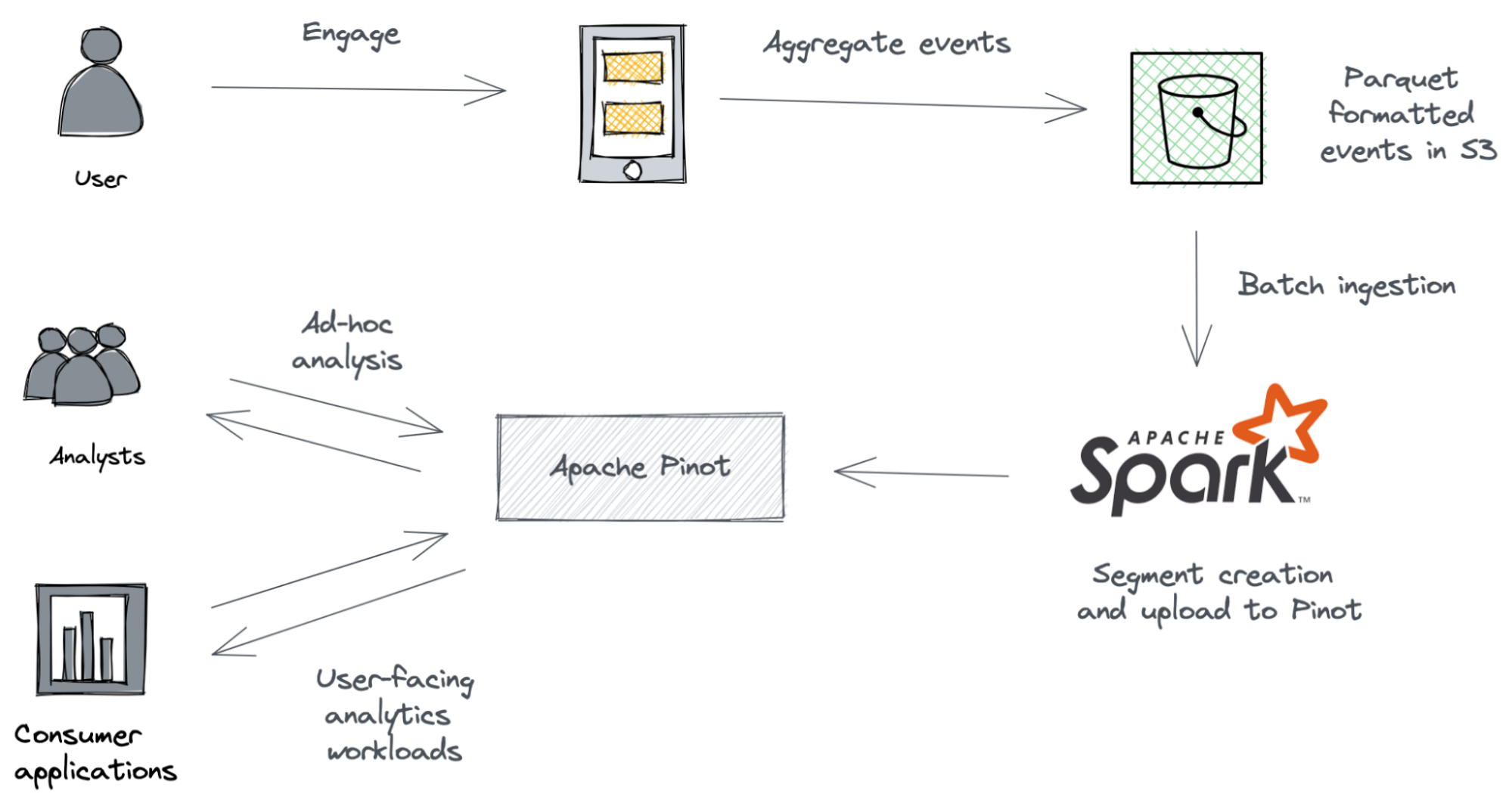 Architecture
Architecture
Launch Pinot Cluster
Once you have everything ready, follow this guide (opens in a new tab) to spin up a single-node Pinot cluster.
You can start Pinot using the quick-start-batch launcher script.
bin/quick-start-batch.shPrepare the input data set
To simulate the mobile app events, we will use a sample CSV file that you can download from here (opens in a new tab). Having this file in CSV format helps us to spot errors and correct them quickly.
Convert the CSV file into Parquet
Once you have downloaded the file, we will convert it into Parquet format using Apache Spark.
To do that, open up a terminal and navigate to the location where you’ve extracted the Spark distribution. Then execute the following command to launch the Spark-scala shell. We are using Spark shell here as we don’t want to write a fully-fledged Spark script to get this done.
<SPARK_HOME>/bin/spark-shellOnce the shell is running, execute the below commands in the shell.
val df = spark.read.format("csv").option("header", true).load("/path/to/events.csv")
df.write.option("compression","none").mode("overwrite").parquet("/path/to/output")The first command above creates a Spark data frame out of the CSV file. Make sure to provide the exact location of the CSV file. The second command writes the data frame as a Parquet file into the path specified.
If the Spark job was successful, you should see .parquet files inside the /path/to/output directory.
Upload the Parquet file to S3
Now we have our Parquet file in place. Let’s go ahead and upload that into an S3 bucket.
You can use AWS CLI or AWS console for that based on your preference.
We will use the AWS CLI to upload the Parquet files into an S3 bucket called pinot-spark-demo:
aws s3 cp /path/to/output s3://pinot-spark-demo/rawdata/ --recursiveCreate a table and schema
We need to create a table to query the data that will be ingested. All tables in Pinot are associated with a schema. You can check out the Table configuration (opens in a new tab) and Schema configuration (opens in a new tab) for more details.
Create a file called events_schema.json with a text editor and add the following content.
That represents the schema definition to capture events.
{
"schemaName": "events",
"dimensionFieldSpecs": [
{
"name": "eventId",
"dataType": "STRING"
},
{
"name": "userId",
"dataType": "INT"
},
{
"name": "eventType",
"dataType": "STRING"
}
],
"metricFieldSpecs": [],
"dateTimeFieldSpecs": [
{
"name": "ts",
"dataType": "LONG",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}events_schema.json
Notice that the attribute ts has been defined under the date-time section. We will be filtering events using the timestamp attribute. Hence, we explicitly declared ts as a data-time field candidate.
Create another file called events_table.json with the following content.
That represents the events table.
{
"tableName": "events",
"segmentsConfig": {
"timeColumnName": "ts",
"timeType": "MILLISECONDS",
"replication": "1",
"schemaName": "events"
},
"tableIndexConfig": {
"invertedIndexColumns": [],
"loadMode": "MMAP"
},
"tenants": {
"broker": "DefaultTenant",
"server": "DefaultTenant"
},
"tableType": "OFFLINE",
"metadata": {}
}events_table.json
On a terminal, navigate to the location where Pinot distribution is running.
Execute the following command from the <PINOT_HOME>/bin directory to define events schema and the table.
./pinot-admin.sh AddTable \
-tableConfigFile /path/to/events_table.json \
-schemaFile /path/to/events_schema.json -execIf the above command is successful, you should see the events schema and table that has been created inside Pinot data explorer, which you can access over at http://localhost:9000/ (opens in a new tab).
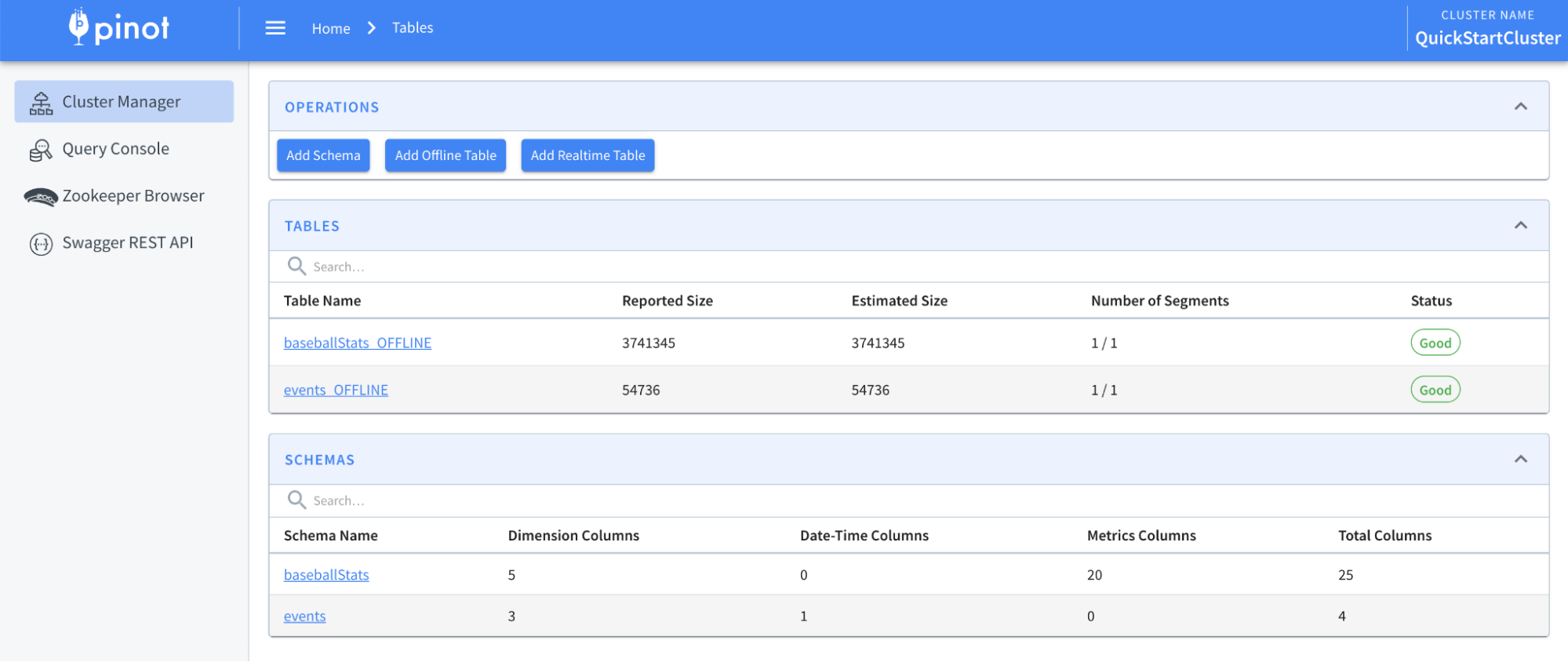 Table Overview
Table Overview
Ingest data from S3
Now that we have an empty table inside Pinot. Let’s go ahead and ingest the Parquet files in the S3 bucket into the running Pinot instance.
Batch Data ingestion in Pinot involves the following steps.
- Read data and generate compressed segment files from the input
- Upload the compressed segment files to the output location
- Push the location of the segment files to the controller
This process can be illustrated as follows.
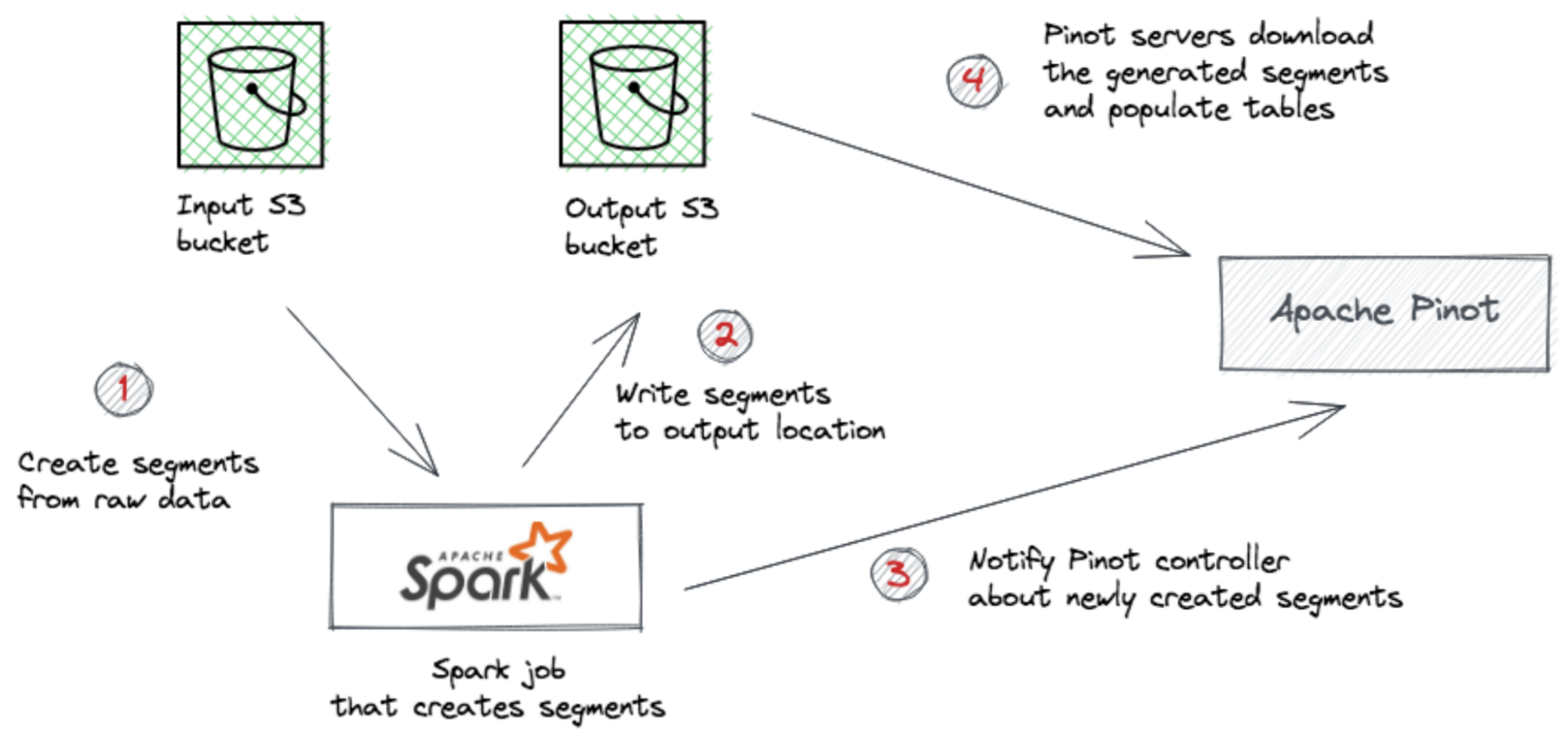 Spark Data Ingestion
Spark Data Ingestion
Once the location is available to the controller, it can notify the servers to download the segment files and populate the tables.
The above steps can be performed using any distributed executor of your choice, such as Hadoop, Spark, Flink, etc. For this tutorial, we will be using Apache Spark to execute the steps.
Pinot provides runners for Spark out of the box. As a user, you don’t need to write a single line of code. You can write runners for any other executor using our provided interfaces.
Let’s create a specification file for the data ingestion job and name it as events-s3.yml. Add the following content to it.
executionFrameworkSpec:
name: spark
segmentGenerationJobRunnerClassName: >-
org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentGenerationJobRunner
segmentTarPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentTarPushJobRunner
segmentUriPushJobRunnerClassName: org.apache.pinot.plugin.ingestion.batch.spark.SparkSegmentUriPushJobRunner
jobType: SegmentCreationAndMetadataPush
inputDirURI: 's3://pinot-spark-demo/rawdata'
outputDirURI: 's3://pinot-spark-demo/output/'
overwriteOutput: true
pinotFSSpecs:
- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: us-east-1
recordReaderSpec:
dataFormat: parquet
className: org.apache.pinot.plugin.inputformat.parquet.ParquetRecordReader
tableSpec:
tableName: events
schemaURI: 'http://localhost:9000/tables/events/schema'
tableConfigURI: 'http://localhost:9000/tables/events'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'
pushJobSpec:
pushParallelism: 2
pushAttempts: 2
pushRetryIntervalMillis: 1000events-s3.yml
We have kept the execution framework as Spark in the job specification and configured the appropriate runners for each of our steps.
Also we set the ingestion jobType as SegmentCreationAndMetadataPush, which is more performant and lightweight for the controller.
When using this jobType, make sure that controllers and servers have access to the outputDirURI so that they can download segments from directly.
Other supported jobTypes are:
- SegmentCreation
- SegmentTarPush
- SegmentUriPush
- SegmentCreationAndTarPush
- SegmentCreationAndUriPush
- SegmentCreationAndMetadataPush
We also provide the S3 Filesystem and Parquet reader implementation in the config to use. You can refer to Ingestion Job Spec (opens in a new tab) for a complete list of configurations.
Once everything is in place, let’s kick off the ingestion job by executing the below command.
export PINOT_VERSION=0.8.0
export PINOT_DISTRIBUTION_DIR=/path/to/apache-pinot-0.8.0-bin
export SPARK_HOME=/path/to/spark-2.4.8-bin-hadoop2.7
cd ${PINOT_DISTRIBUTION_DIR}
${SPARK_HOME}/bin/spark-submit \
--class org.apache.pinot.tools.admin.command.LaunchDataIngestionJobCommand \
--master "local[2]" \
--deploy-mode client \
--conf "spark.driver.extraJavaOptions=-Dplugins.dir=${PINOT_DISTRIBUTION_DIR}/plugins -Dlog4j2.configurationFile=${PINOT_DISTRIBUTION_DIR}/conf/pinot-ingestion-job-log4j2.xml" \
--conf "spark.driver.extraClassPath=${PINOT_DISTRIBUTION_DIR}/plugins/pinot-batch-ingestion/pinot-batch-ingestion-spark/pinot-batch-ingestion-spark-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar:${PINOT_DISTRIBUTION_DIR}/plugins/pinot-file-system/pinot-s3/pinot-s3-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/plugins/pinot-input-format/pinot-parquet/pinot-parquet-${PINOT_VERSION}-shaded.jar:${PINOT_DISTRIBUTION_DIR}/plugins/pinot-file-system/pinot-hdfs/pinot-hdfs-${PINOT_VERSION}-shaded.jar" \
local://${PINOT_DISTRIBUTION_DIR}/lib/pinot-all-${PINOT_VERSION}-jar-with-dependencies.jar \
-jobSpecFile '/Users/dunith/Work/ingestion-specs/events-s3.yml'Make sure to replace the values for PINOT_DISTRIBUTION_DIR and SPARK_HOME to match with your local environment.
The above command includes the JARs of all the required plugins in Spark’s driver classpath. In practice, you only need to do this if you get a ClassNotFoundException.
The command will take a few seconds to complete based on your machine’s performance.
If the ingestion job doesn’t throw out any errors to the console, that means you have successfully populated the events table with data coming from the S3 bucket.
The data explorer shows the populated events table as follows.
Querying Pinot to calculate the daily active users (DAU)
Here comes the exciting part. Now we have data ingested into Pinot. Let’s write some SQL queries to calculate DAU based on the user engagement events.
The mobile app has been released to the public. Its audience will grow daily. The first time users install the app, some will continue to use it regularly or from time to time, and some will quickly lose interest. However, these user segments are considered active because they had at least one session in the app at a particular time.
Let’s use SQL to calculate the number of unique users in the last three months.
Copy and paste the following query into the Query console and run.
select ToDateTime(ts, 'yyyy-MM-dd') as t_date, count(distinct userId) as DAU
from events
where ts > now() - 86400000*30*3
group by t_date
order by 1 ascThat should result in the following output:
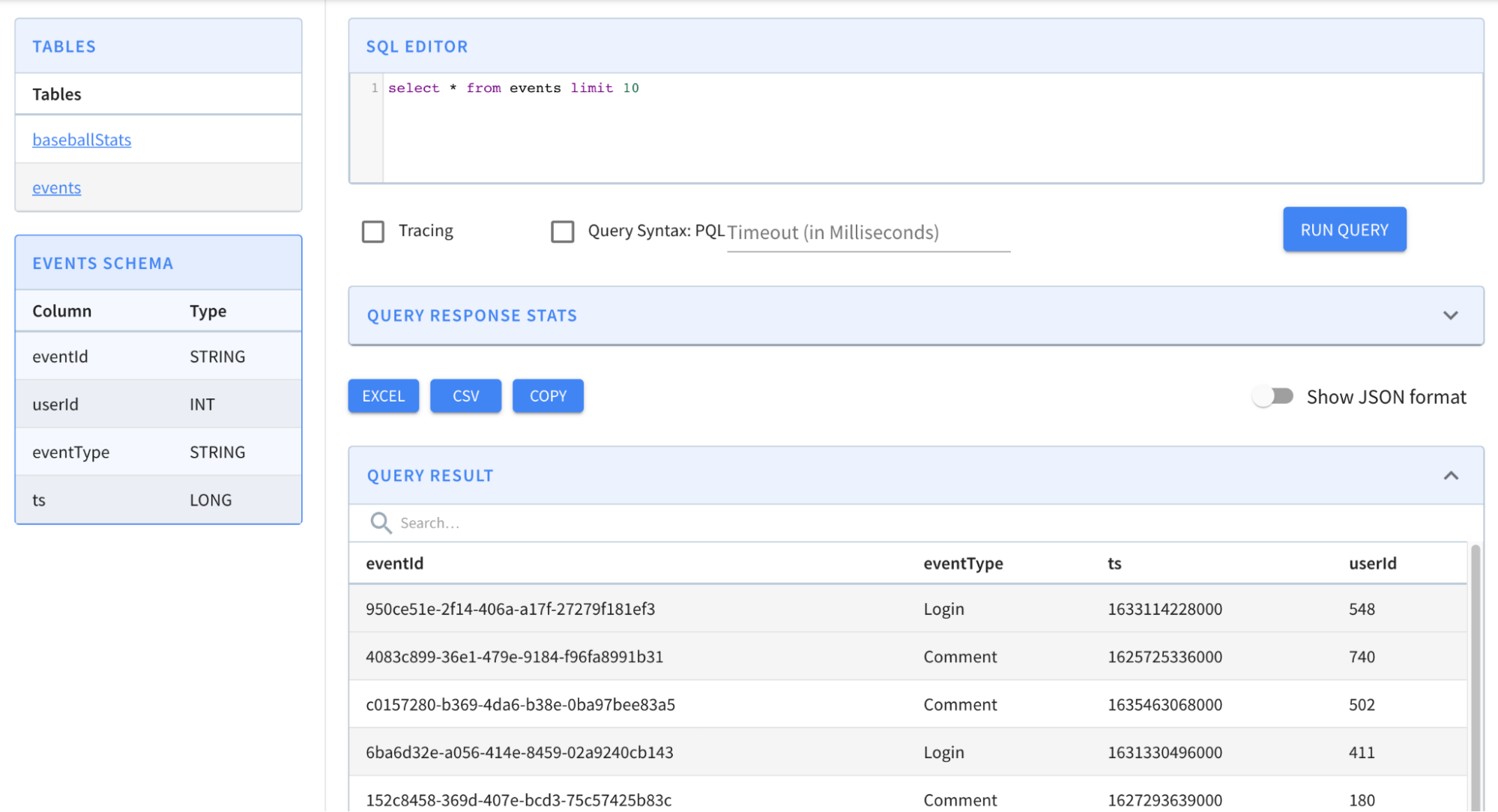 Query Results
Query Results
What next?
Now we have seen the power of Pinot’s pluggable architecture. It enables you to mix and match different data source implementations and input formats to optimize your data ingestion strategy.
In a data-driven organization, that flexibility allows data engineers to build data pipelines that cater to various data sources and workloads. For example, you can switch from an on-premise HDFS storage to a cloud data lake like S3 just by changing a few lines in the ingestion specification.
Data analysts and data scientists will also benefit from Pinot’s ability to ingest vast amounts of data from data lakes and give them low-latency access to exploratory analysis.
You can take this tutorial to the next level by configuring a data visualization like Apache Superset, which complements the interactive analysis by giving you more visualization capabilities.