Ingest CSV files from a S3 bucket
In this recipe, we will learn how Pinot can be configured to ingest CSV files from an AWS S3 bucket.
Prerequisites
You will need a running Pinot cluster locally to follow the code examples in this guide.
Make sure you have the following configured in the machine that you are going to deploy Apache Pinot.
- A valid account in AWS.
- A local installation of AWS CLI along with your credentials configured (opens in a new tab).
- An AWS access key (opens in a new tab) for having programmatic access to S3.
Create an S3 bucket
Let's create an S3 bucket called pinot-demo to keep the source CSV files.
You can use the AWS CLI to do that.
aws s3 mb s3://pinot-demoCopy CSV files
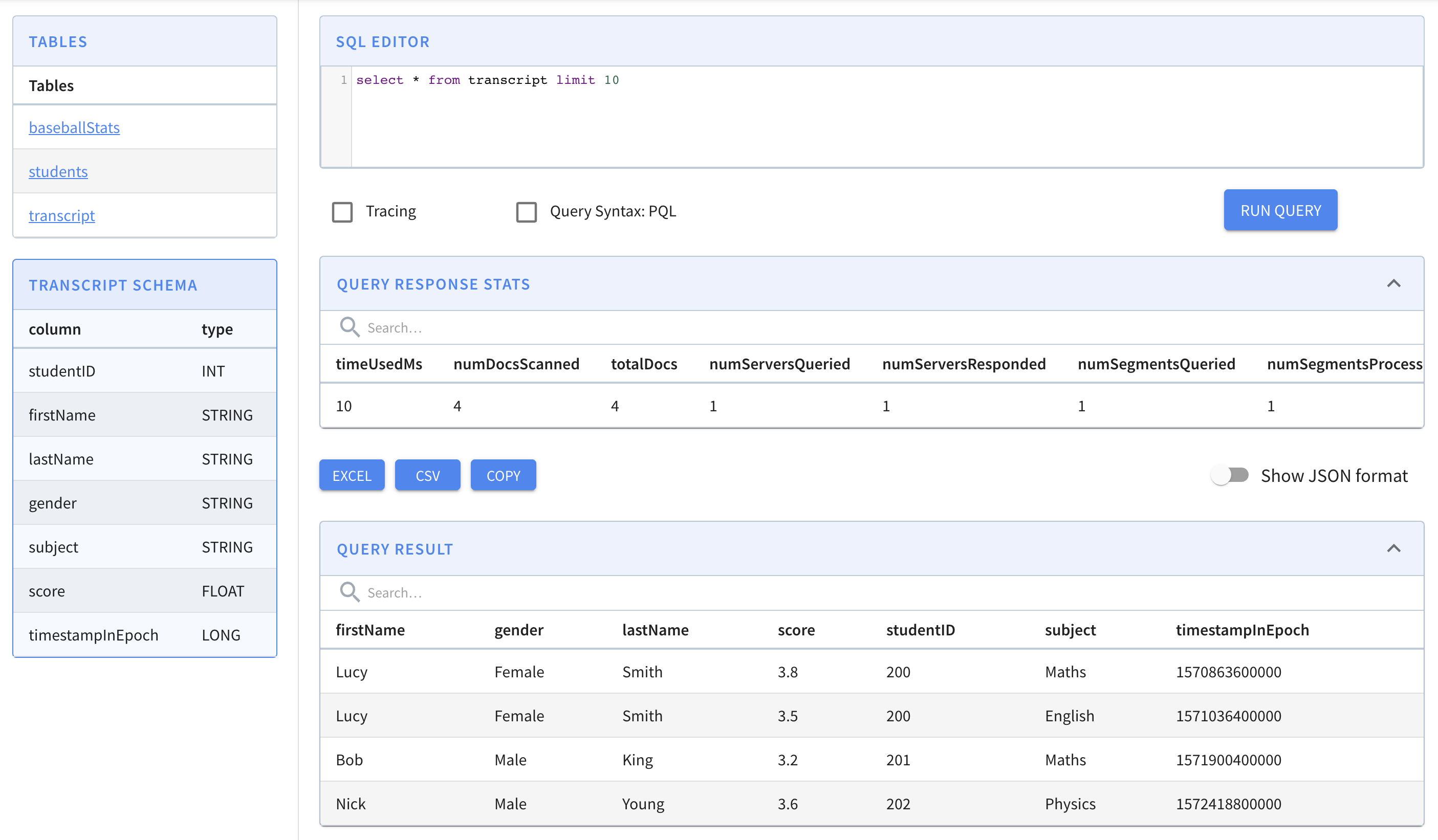
Create a CSV file called transcript.csv with the following content.
studentID,firstName,lastName,gender,subject,score,timestampInEpoch
200,Lucy,Smith,Female,Maths,3.8,1570863600000
200,Lucy,Smith,Female,English,3.5,1571036400000
201,Bob,King,Male,Maths,3.2,1571900400000
202,Nick,Young,Male,Physics,3.6,1572418800000Now, copy that file into S3 bucket using the CLI.
aws s3 cp transcript.csv s3://pinot-demo/rawdata/transcript.csvConfigure Pinot
Now that we have the CSV file in the S3 bucket. Let's configure Pinot to ingest it and create a segment out of it. First, let's create a schema and a table definition for the transcript data set.
Create the transcript_schema.json as follows.
{
"schemaName": "transcript",
"dimensionFieldSpecs": [
{
"name": "studentID",
"dataType": "INT"
},
{
"name": "firstName",
"dataType": "STRING"
},
{
"name": "lastName",
"dataType": "STRING"
},
{
"name": "gender",
"dataType": "STRING"
},
{
"name": "subject",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "score",
"dataType": "FLOAT"
}
],
"dateTimeFieldSpecs": [{
"name": "timestampInEpoch",
"dataType": "LONG",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}Create the transcript_table.json as follows.
{
"tableName": "transcript",
"segmentsConfig" : {
"timeColumnName": "timestampInEpoch",
"timeType": "MILLISECONDS",
"replication" : "1",
"schemaName" : "transcript"
},
"tableIndexConfig" : {
"invertedIndexColumns" : [],
"loadMode" : "MMAP"
},
"tenants" : {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableType":"OFFLINE",
"metadata": {}
}Upload the table using following command.
bin/pinot-admin.sh AddTable \
-tableConfigFile transcript_table.json \
-schemaFile transcript_schema.json -execCreate the ingestion job spec file
Create a file called job-spec.yml and add the following content to it.
executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: 's3://pinot-demo/rawdata/'
includeFileNamePattern: 'glob:**/*.csv'
outputDirURI: 's3://pinot-demo/segments'
overwriteOutput: true
pinotFSSpecs:
- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: us-east-1
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'transcript'
pinotClusterSpecs:
- controllerURI: 'http://localhost:9000'Let's break down this specification further for better understanding.
The following configuration block instructs Pinot to use S3 as the underlying file system implementation, with the className pointing to the implementation class.
pinotFSSpecs:
- scheme: s3
className: org.apache.pinot.plugin.filesystem.S3PinotFS
configs:
region: us-east-1Below, inputDirURI specifies the S3 bucket location where Pinot should ingest the data from. If you remember, we copied the transcript.csv file into that folder. The directive includeFileNamePattern filters all CSV files in that folder.
Once the ingestion is completed, Pinot writes the segments into the location specified by outputDirURI
inputDirURI: 's3://pinot-demo/rawdata/'
includeFileNamePattern: 'glob:**/*.csv'
outputDirURI: 's3://pinot-demo/segments'We are reading CSV files. Hence, the following configuration block uses the CSV record reader format.
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'Initiate the ingestion job
Now we have everything in place. Let's go ahead and kick off the ingestion by running:
bin/pinot-admin.sh LaunchDataIngestionJob \
-jobSpecFile job-spec.ymlOnce it is completed, you should see the transcript table populated with data in the Query Console (opens in a new tab).