Indexing Geospatial points
To learn how to index and query geospatial points in Apache Pinot, watch the following video, or complete the tutorial below, starting with Prerequites.
To learn about geospatial objects, see the Geospatial objects developer guide.
| Pinot Version | 1.0.0 |
| Code | startreedata/pinot-recipes/geospatial-indexing |
Prerequisites
To follow the code examples in this guide, you must install Docker (opens in a new tab) locally and download recipes.
Navigate to recipe
- If you haven't already, download recipes.
- In terminal, go to the recipe by running the following command:
cd pinot-recipes/recipes/geospatial-indexingLaunch Pinot Cluster
You can spin up a Pinot Cluster by running the following command:
docker-compose upThis command will run a single instance of the Pinot Controller, Pinot Server, Pinot Broker, Kafka, and Zookeeper. You can find the docker-compose.yml (opens in a new tab) file on GitHub.
Generating Geospatial data
This recipe contains a data generator that produces JSON documents that contain various geospatial objects in Well-known text (WKT) (opens in a new tab) format.
You'll need to first install the following dependencies:
pip install geofactory faker geojson shapelyOnce that's done you can run the data generator and grab just the first generated document, by running the following command:
python datagen.py 2>/dev/null | head -n1 | jqOutput is shown below:
{
"tsString": 1677845139617,
"uuid": "362ec33c-6bd3-4928-8123-11ebe6a50c07",
"count": 552,
"pointString": "POINT (108.249223 5.520676)"
}You can see from this output that we have a geospatial point. Pinot also supports polygons, mutli polygons, line strings, multi points, multi line strings, and geometry collections. You can read more about this in the Geospatial documention (opens in a new tab).
Kafka ingestion
We're going to ingest this data into an Apache Kafka topic using the kcat (opens in a new tab) command line tool.
We'll also use jq to structure the data in the key:payload structure that Kafka expects:
python datagen.py --sleep 0.0001 2>/dev/null |
jq -cr --arg sep ø '[.uuid, tostring] | join($sep)' |
kcat -P -b localhost:9092 -t events -KøWe can check that Kafka has some data by running the following command:
docker exec -it kafka-geospatial kafka-run-class.sh \
kafka.tools.GetOffsetShell \
--broker-list localhost:9092 \
--topic eventsWe'll see something like the following:
events:0:138780Pinot Schema and Table
Now let's create a Pinot Schema and Table.
First, the schema:
{
"schemaName": "events_geo",
"dimensionFieldSpecs": [
{"name": "uuid", "dataType": "STRING"},
{"name": "point", "dataType": "BYTES"}
],
"metricFieldSpecs": [{"name": "count", "dataType": "INT"}],
"dateTimeFieldSpecs": [
{
"name": "ts",
"dataType": "TIMESTAMP",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}Note that the column for point has a data type of BYTES.
Geospatial columns must use the BYTES type because Pinot will serialize the Geospatial objects into bytes for storage purposes.
Now for the table config:
{
"tableName": "events_geo",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "ts",
"schemaName": "events_geo",
"replication": "1",
"replicasPerPartition": "1"
},
"fieldConfigList": [
{
"name": "point",
"encodingType": "RAW",
"indexType": "H3",
"properties": {
"resolutions": "5"
}
}
],
"tableIndexConfig": {
"loadMode": "MMAP",
"noDictionaryColumns": ["point"],
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.topic.name": "events",
"stream.kafka.broker.list": "kafka-geospatial:9093",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"realtime.segment.flush.threshold.rows":"100000",
"realtime.segment.flush.threshold.time":"1h"
}
},
"ingestionConfig": {
"transformConfigs": [
{
"columnName": "point",
"transformFunction": "toSphericalGeography(ST_GeomFromText(pointString))"
}
]
},
"tenants": {},
"metadata": {}
}The highlighted lines define a Geospatial index on the point column.
If you scroll down a bit, under ingestionConfig.transformConfigs you can see transformation functions that converts the WKT string from our Kafka streams into a Geospatial object.
We'll create the table by running the following:
docker run \
--network geospatial \
-v $PWD/config:/config \
apachepinot/pinot:1.0.0 AddTable \
-schemaFile /config/schema.json \
-tableConfigFile /config/table.json \
-controllerHost "pinot-controller-geospatial" \
-execWhen is the Geospatial index used?
Now that we've created a table that contains a column with a Geospatial index, it'd be useful to know when that index will be used.
This index is used when a variety of predicates appear in the WHERE clause of a query.
ST_Distance
The ST_Distance function computes the distance in meters between two sets of coordinates.
When used with this function, one of the arguments must be an identifer (i.e. column name) and the other a literal value.
The result of calling ST_Distance must then be used in a range query i.e. it should be less than or greater than a specified distance.
Examples are shown below:
WHERE ST_Distance(point, '<Literal representing Point, Polygon, LineString, or GeometryCollection>') > 5000
WHERE ST_Distance('<Literal representing Point, Polygon, LineString, or GeometryCollection>', point) < 2000`ST_Within
ST_Within checks the containment of two geospatial objects. It returns true if and only if the first geometry is completely inside the second geometry.
When used with this function, the first argument must be an identifier (i.e. column name) and the other a literal value. An example is shown below:
WHERE ST_Within(point, '<Literal representing a geometry object>')ST_Contains
ST_Contains also checks the containment of two geospatial objects. More specifically, it returns true if and only if no points of the second geometry lie in the exterior of the first geometry, and at least one point of the interior of the first geometry lies in the interior of the second geometry.
When used with this function, the first argument must be a literal and the other an identifier (i.e. column name). An example is shown below:
WHERE ST_Contains('<Literal representing a geometry object>', point)Geospatial Querying
Now let's head on over to the Pinot UI (opens in a new tab) and write some queries that use the Geospatial index.
The following query counts how many points fit inside a polygon that covers an area from Delaware to West Virginia (opens in a new tab).
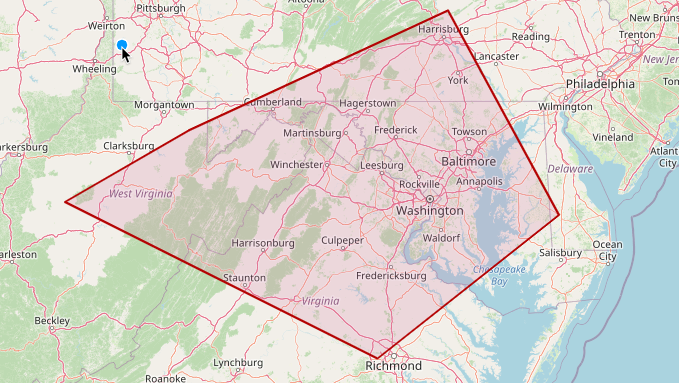 A polygon covering an area from Delaware to West Virginia
A polygon covering an area from Delaware to West Virginia
select count(*)
from events_geo
WHERE ST_Within(
point,
toSphericalGeography(ST_GeomFromText('POLYGON((
-79.68778610229492 39.475226764883985,
-76.83970928192137 40.48289486417028,
-75.6193685531616 38.75281151479021,
-77.61510372161864 37.51568305958246,
-81.04884624481201 38.86621021801801,
-79.68778610229492 39.475226764883985))'))
) = 1
limit 1| count(*) |
|---|
| 747 |
Query Results
We can flip that query around to use ST_Contains like this:
select count(*)
from events_geo
WHERE ST_Contains(
toSphericalGeography(ST_GeomFromText('POLYGON((
-79.68778610229492 39.475226764883985,
-76.83970928192137 40.48289486417028,
-75.6193685531616 38.75281151479021,
-77.61510372161864 37.51568305958246,
-81.04884624481201 38.86621021801801,
-79.68778610229492 39.475226764883985))')),
point
) = 1
limit 1This query will return the same results as the previous one.
Finally, we can find some of the points within 50km of Washington:
select uuid, ST_AsText(point), ts,
ST_Distance(point, toSphericalGeography(ST_GeomFromText(
'POINT(-77.39327430725099 38.93217314143698)'))) AS distance
from events_geo
WHERE distance < 50000
limit 10| uuid | stastext(point) | ts | distance |
|---|---|---|---|
| 1a9a7314-7550-4327-9fb5-911f636b869c | POINT (-77.729246 39.255027) | 2023-03-06 14:27:59.218 | 46146.138375698916 |
| f6d3260b-93d7-478c-b7b1-2dfc214a09dc | POINT (-77.796573 39.060015) | 2023-03-06 14:40:17.591 | 37640.39151993725 |
| 51693e80-cdd3-48d6-af53-78156357a5dc | POINT (-77.751046 39.115125) | 2023-03-06 14:40:17.591 | 37000.762022801944 |
| fafe2a9c-ca39-4dd2-bf55-37013a1e2719 | POINT (-77.569928 39.292096) | 2023-03-06 14:04:46.509 | 42825.54468861071 |
| d5329e92-edf7-4733-816e-9f2e2c580c2d | POINT (-77.188892 39.187191) | 2023-03-06 14:04:46.509 | 33399.262939756285 |
| 9b7cba1f-a2e4-4690-bba9-48b71f50b915 | POINT (-77.053764 38.896884) | 2023-03-06 14:04:46.509 | 29635.04964656463 |
| 1b5d5a0e-1a6b-46fb-85b4-42e5c0e208e5 | POINT (-77.618947 38.881897) | 2023-03-06 13:38:18.331 | 20311.553153107612 |
| 1639f1eb-fb60-4f94-9c59-d7e595c8f416 | POINT (-76.960903 38.772332) | 2023-03-06 14:12:30.667 | 41445.58284663461 |
Query Results
How do I check that the Geospatial index is being used?
We can check that the Geospatial index is being used by prefixing a query with EXPLAIN PLAN FOR, which will return the query plan.
To get the query plan for the ST_Distance function, we'd write the following:
EXPLAIN PLAN FOR
select uuid, ST_AsText(point), ts,
ST_Distance(point, toSphericalGeography(ST_GeomFromText(
'POINT(-77.39327430725099 38.93217314143698)'))) AS distance
from events_geo
WHERE distance < 50000
limit 10| Operator | Operator_Id | Parent_Id |
|---|---|---|
| BROKER_REDUCE(limit:10) | 1 | 0 |
| COMBINE_SELECT | 2 | 1 |
| PLAN_START(numSegmentsForThisPlan:71) | -1 | -1 |
| SELECT(selectList:uuid, stastext(point), ts, st_distance(point,'80c053592b680000014043775173125738')) | 3 | 2 |
| TRANSFORM(st_distance(point,'80c053592b680000014043775173125738'), stastext(point), ts, uuid) | 4 | 3 |
| PROJECT(uuid, point, ts) | 5 | 4 |
| DOC_ID_SET | 6 | 5 |
| FILTER_H3_INDEX(indexLookUp:h3_index,operator:RANGE, predicate:st_distance( point,'80c053592b680000014043775173125738') < '50000') | 7 | 6 |
Query Results
We must see FILTER_H3_INDEX as one of the operators, otherwise the index isn't being used.
We can do the same thing for the ST_Within and ST_Contains queries.
We should see the INCLUSION_FILTER_H3_INDEX operator for both these queries:
For ST_Within, we'll see the following plan:
| Operator | Operator_Id | Parent_Id |
|---|---|---|
| BROKER_REDUCE(limit:1) | 1 | 0 |
| COMBINE_AGGREGATE | 2 | 1 |
| PLAN_START(numSegmentsForThisPlan:75) | -1 | -1 |
| AGGREGATE(aggregations:count(*)) | 3 | 2 |
| TRANSFORM_PASSTHROUGH() | 4 | 3 |
| PROJECT() | 5 | 4 |
| DOC_ID_SET | 6 | 5 |
| INCLUSION_FILTER_H3_INDEX(inclusionIndex:h3_index,operator:EQ, predicate:stwithin(point,'84000000010000000600000000c053ec04b00000004043bcd43b0aae 28c05335bdcbffffff40443dcf7fb88244c052e7a3bbffffff4043605c20b209c0c053675ddb ffffff4042c201e70a0102c05443204c00000040436edff9f6ec98c053e c04b00000004043bcd43b0aae28') = '1') | 7 | 6 |
Query Results
Notice that the INCLUSION_FILTER_H3_INDEX operator contains the stwithin predicate.
And for ST_Contains, we'll see this plan:
| Operator | Operator_Id | Parent_Id |
|---|---|---|
| BROKER_REDUCE(limit:1) | 1 | 0 |
| COMBINE_AGGREGATE | 2 | 1 |
| PLAN_START(numSegmentsForThisPlan:75) | -1 | -1 |
| AGGREGATE(aggregations:count(*)) | 3 | 2 |
| TRANSFORM_PASSTHROUGH() | 4 | 3 |
| PROJECT() | 5 | 4 |
| DOC_ID_SET | 6 | 5 |
| INCLUSION_FILTER_H3_INDEX(inclusionIndex:h3_index,operator:EQ, predicate:stcontains('84000000010000000600000000c053ec04b00000004043bcd43b0aae 28c05335bdcbffffff40443dcf7fb88244c052e7a3bbffffff4043605c20b209c0c053675ddb ffffff4042c201e70a0102c05443204c00000040436edff9f6ec98c053e c04b00000004043bcd43b0aae28',point) = '1') | 7 | 6 |
Query Results
And notice on this one that the INCLUSION_FILTER_H3_INDEX operator contains the stcontains predicate.