How to manually schedule real-time to offline job
In this recipe we'll learn how to manually schedule Apache Pinot's Real-Time to Offline job. This job is used to transition data from real-time to offline tables. For background reading on the use case for doing this, see Managed Offline Flow.
| Pinot Version | 0.9.3 |
| Code | startreedata/pinot-recipes/managed-offline-flow |
Prerequisites
To follow the code examples in this guide, you must install Docker (opens in a new tab) locally and download recipes.
Navigate to recipe
- If you haven't already, download recipes.
- In terminal, go to the recipe by running the following command:
cd pinot-recipes/recipes/managed-offline-flowLaunch Pinot Cluster
You can spin up a Pinot Cluster by running the following command:
docker-compose upThis command will run a single instance of the Pinot Controller, Pinot Server, Pinot Broker, Pinot Minion, Kafka, and Zookeeper. You can find the docker-compose.yml (opens in a new tab) file on GitHub.
Pinot Schema and Tables
Now let's create a Pinot Schema, as well as real-time and offline tables. Pinot is going to take care of populating data into the offline table, but it still expects us to configure the table.
Schema
Our schema is going to capture some simple events, and looks like this:
{
"schemaName": "events",
"dimensionFieldSpecs": [
{
"name": "uuid",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "count",
"dataType": "INT"
}
],
"dateTimeFieldSpecs": [{
"name": "ts",
"dataType": "TIMESTAMP",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}config/schema.json
You can create the schema by running the following command:
docker exec -it pinot-controller-rt bin/pinot-admin.sh AddSchema \
-schemaFile /config/schema.json \
-execOffline Table
The offline table config is defined below:
{
"tableName": "events",
"tableType": "OFFLINE",
"segmentsConfig": {
"timeColumnName": "ts",
"schemaName": "events",
"replication": "1",
"replicasPerPartition": "1"
},
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "HOURLY"
}
},
"tableIndexConfig": {
"loadMode": "MMAP"
},
"tenants": {},
"metadata": {}
}config/table-offline.json
You can create the table by running the following command:
docker exec -it pinot-controller-rt bin/pinot-admin.sh AddTable \
-tableConfigFile /config/table-offline.json \
-execReal-Time Table
And the real-time table is defined below:
{
"tableName": "events",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "ts",
"schemaName": "events",
"replication": "1",
"replicasPerPartition": "1",
"retentionTimeUnit": "DAYS",
"retentionTimeValue": "1"
},
"task": {
"taskTypeConfigsMap": {
"RealtimeToOfflineSegmentsTask": {
"bufferTimePeriod": "1m",
"bucketTimePeriod": "5m",
"roundBucketTimePeriod": "1m",
"schedule": "0 * * * * ?",
"mergeType": "rollup",
"count.aggregationType": "max",
"maxNumRecordsPerSegment": "100000"
}
}
},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.topic.name": "events",
"stream.kafka.broker.list": "kafka-rt:9093",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"realtime.segment.flush.threshold.rows": "10000",
"realtime.segment.flush.threshold.time": "1h",
"realtime.segment.flush.threshold.segment.size": "5M"
}
},
"tenants": {},
"metadata": {}
}config/table-realtime.json
The realtime.segment.flush.threshold.rows config is intentionally set to an extremely small value so that the segment will be committed after 10,000 records have been ingested.
In a production system this value should be set much higher, as described in the configuring segment threshold guide.
The main thing that we're interested in is the RealtimeToOfflineSegmentsTask, which is extracted below:
"task": {
"taskTypeConfigsMap": {
"RealtimeToOfflineSegmentsTask": {
"bufferTimePeriod": "1m",
"bucketTimePeriod": "5m",
"roundBucketTimePeriod": "1m",
"mergeType": "rollup",
"count.aggregationType": "max",
"maxNumRecordsPerSegment": "100000"
}
}
}This configuration enables the job and defines what should happen when it runs. Let's understand what each of the parameters does:
-
bufferTimePeriod- Tasks won't be scheduled unless the time window is older than this buffer. -
bucketTimePeriod- The time window size/amount of data processed for each run.
The values for bufferTimePeriod and bucketTimePeriod are intentionally set to very low values so that it's easier to see how they work.
In a production setup, these values would usually be set to a time of 1 day or more.
-
roundBucketTimePeriod- Round the time value before merging rows in the offline table. The value of1mthat we've used means that values in thetscolumn will be rounded to the nearest column. -
mergeType- The type of aggregation to apply when creating rows in the offline table. Valid values are:concat- Don't aggregate anything.rollup- Perform metric aggregations across common dimensions and time.dedup- Deduplicate rows that have the same values.
-
{metricName}.aggregationType- Aggregation function to apply to the metric for aggregations. Only applicable forrollup. Allowed values aresum,max, andmin. We are selecting themaxvalue for thecountcolumn. -
maxNumRecordsPerSegment- The number of records to include in a segment.
You can create the table by running the following command:
docker exec -it pinot-controller-rt bin/pinot-admin.sh AddTable \
-tableConfigFile /config/table-realtime.json \
-execIngesting Data
Let's ingest data into the events Kafka topic, by running the following:
while true; do
ts=`date +%s%N | cut -b1-13`;
uuid=`cat /proc/sys/kernel/random/uuid | sed 's/[-]//g'`
count=$[ $RANDOM % 1000 + 0 ]
echo "{\"ts\": \"${ts}\", \"uuid\": \"${uuid}\", \"count\": $count}"
done |
docker exec -i kafka-rt /opt/kafka/bin/kafka-console-producer.sh \
--bootstrap-server localhost:9092 \
--topic eventsData will make its way into the real-time table. We can see how many records have been ingested by running the following query:
SELECT count(*)
FROM eventsScheduling the RT2OFF Job
The Real-Time to Offline Job can be scheduled automatically via the real-time table config or manually via the REST API. We can trigger it manually by running the following command:
curl -X POST "http://localhost:9000/tasks/schedule?taskType=RealtimeToOfflineSegmentsTask&tableName=events_REALTIME" \
-H "accept: application/json" 2>/dev/null | jq '.'Output
{
"RealtimeToOfflineSegmentsTask": "Task_RealtimeToOfflineSegmentsTask_1646672575118"
}We can then check the Pinot Controller logs to see that it's been triggered:
docker exec -it pinot-controller-rt grep -rni --color "\[RealtimeToOff" logs/pinot-all.logOutput
2022/03/07 17:02:54.999 INFO [RealtimeToOfflineSegmentsTaskGenerator] [grizzly-http-server-8] Start generating task configs for table: events_REALTIME for task: RealtimeToOfflineSegmentsTask
2022/03/07 17:02:55.118 INFO [RealtimeToOfflineSegmentsTaskGenerator] [grizzly-http-server-8] Finished generating task configs for table: events_REALTIME for task: RealtimeToOfflineSegmentsTaskLet's run the job a few times and then navigate to localhost:9000/#/tables (opens in a new tab). You'll see the following:
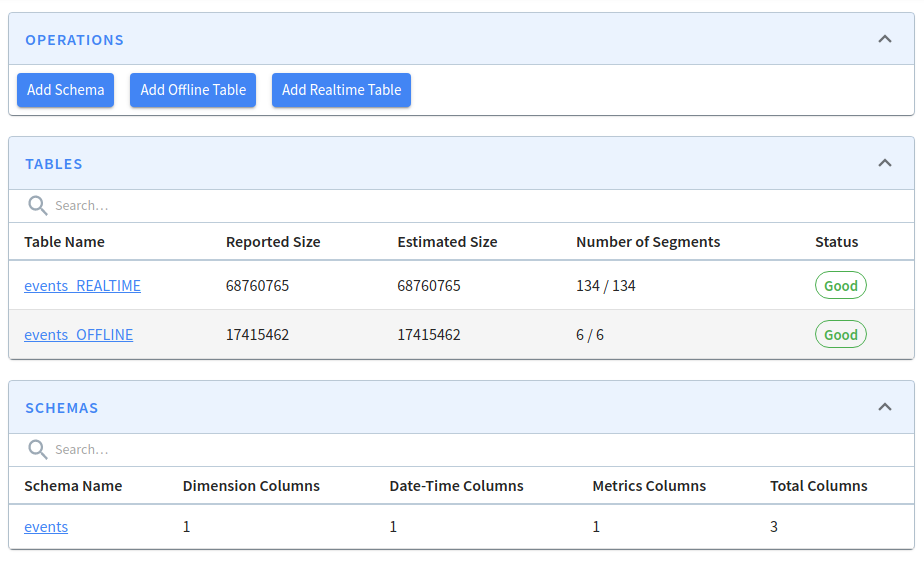 Real-Time and Offline Tables
Real-Time and Offline Tables
You can see that some segments have been created in the offline table:
Time Boundary
The data written to segments in offline tables won't immediately be seen in query results. When a query is received by Pinot Brokers, the broker sends a time boundary annotated version of the query to the offline and real-time tables.
For more explanation about how the time boundary is computed, see Concepts: Time Boundary.
The time boundary is based on the value of ingestionConfig.batchIngestionConfig.segmentIngestionFrequency in our offline table:
- If it's set to
HOURLY, thentimeBoundary = Maximum end time of offline segments - 1 HOUR - Otherwise,
timeBoundary = Maximum end time of offline segments - 1 DAY
Our offline table had the following configuration:
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "HOURLY"
}
}This means that the time boundary will be an hour before the maximum end time in offline segments.
You can check the time boundary of a table by querying the HTTP API on the Pinot Broker, as shown in How to work out the time boundary in hybrid tables
In our case the time boundary is set to 1646661240000 or 2022-03-07T13:54:00 in a more friendly format.
This value will increase in increments of 5 minutes every time that the RT2OFF job runs as we set bucketTimePeriod to 5m.
You can increase this value in the real-time table config to have the job process more data.
If we temporarily pause the ingestion, we can check what queries are actually getting executed on each table. Let's say we run the following query to count the number of records:
select count(*)
from events| count(*) |
|---|
| 1450197 |
Query Results
Behind the scenes, the broker sends the following queries to the server:
select count(*)
from events_OFFLINE
WHERE ts <= 1646661240000The first time that you run this query it may return no records since the time stamp will be at least an hour ago and the data in the offline segments will probably be more recent than that.
| count(*) |
|---|
| 26595 |
Query Results
select count(*)
from events_REALTIME
WHERE ts > 1646661240000| count(*) |
|---|
| 1423602 |
Query Results
So it does seem like the query results are combining the offline and real-time tables. This becomes clearer if we write a query that returns the most common timestamps:
select ts, count(*)
from events
GROUP by ts
ORDER BY count(*) DESC
LIMIT 5| ts | count(*) |
|---|---|
| 2022-03-04 15:54:00.0 | 17166 |
| 2022-03-04 15:53:00.0 | 9429 |
| 2022-03-07 16:04:56.059 | 1 |
| 2022-03-07 15:29:59.193 | 1 |
| 2022-03-07 14:55:02.075 | 1 |
Query Results
Recall that when we created offline segments we were rolling up timestamps to the nearest minute, which means that we now have a lot of events with the same timestamp.
Summary
In this guide we've learnt how to move data from a real-time table to an offline table using the Real-Time to Offline job. While doing this transformation we rolled up timestamp data to have a minute instead of millisecond granularity.