How to connect to Dash
In this guide you'll learn how to visualise data from Apache Pinot using Plotly's Dash (opens in a new tab) web framework. Dash is the most downloaded, trusted Python framework for building ML & data science web apps.
We're going to use Dash to build a real-time dashboard to visualise the changes being made to Wikimedia properties.
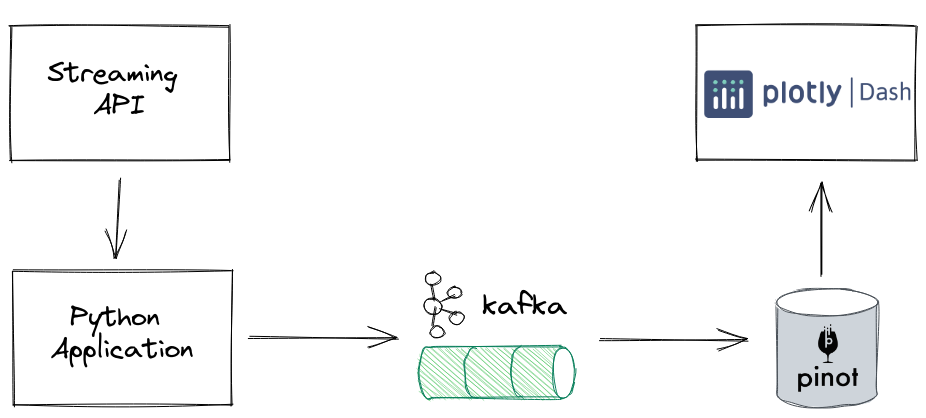 Real-Time Dashboard Architecture
Real-Time Dashboard Architecture
Startup components
We're going to use the following Docker compose file, which spins up instances of Zookeeper, Kafka, along with a Pinot controller, broker, and server:
version: '3.7'
services:
zookeeper:
image: zookeeper:3.5.6
container_name: "zookeeper-wiki"
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: wurstmeister/kafka:latest
restart: unless-stopped
container_name: "kafka-wiki"
ports:
- "9092:9092"
expose:
- "9093"
depends_on:
- zookeeper
environment:
KAFKA_ZOOKEEPER_CONNECT: zookeeper-wiki:2181/kafka
KAFKA_BROKER_ID: 0
KAFKA_ADVERTISED_HOST_NAME: kafka-wiki
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-wiki:9093,OUTSIDE://localhost:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093,OUTSIDE://0.0.0.0:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,OUTSIDE:PLAINTEXT
pinot-controller:
image: apachepinot/pinot:0.10.0
command: "StartController -zkAddress zookeeper-wiki:2181 -dataDir /data"
container_name: "pinot-controller-wiki"
volumes:
- ./config:/config
- ./data:/data
restart: unless-stopped
ports:
- "9000:9000"
depends_on:
- zookeeper
pinot-broker:
image: apachepinot/pinot:0.10.0
command: "StartBroker -zkAddress zookeeper-wiki:2181"
restart: unless-stopped
container_name: "pinot-broker-wiki"
volumes:
- ./config:/config
ports:
- "8099:8099"
depends_on:
- pinot-controller
pinot-server:
image: apachepinot/pinot:0.10.0
command: "StartServer -zkAddress zookeeper-wiki:2181"
restart: unless-stopped
container_name: "pinot-server-wiki"
volumes:
- ./config:/config
depends_on:
- pinot-brokerdocker-compose.yml
Run the following command to launch all the components:
docker-compose upWikimedia recent changes stream
Wikimedia provides provides a continuous stream of structured event data describing changes made to various Wikimedia properties. The events are published over HTTP using the Server-Side Events (SSE) Protocol.
You can find the endpoint at: stream.wikimedia.org/v2/stream/recentchange (opens in a new tab)
We'll need to install the SSE client library to consume this data:
pip install sseclient-pyNext, create a file called wiki.py that contains the following:
import json
import pprint
import sseclient
import requests
def with_requests(url, headers):
"""Get a streaming response for the given event feed using requests."""
return requests.get(url, stream=True, headers=headers)
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
headers = {'Accept': 'text/event-stream'}
response = with_requests(url, headers)
client = sseclient.SSEClient(response)
for event in client.events():
stream = json.loads(event.data)
pprint.pprint(stream)wiki.py
The highlighted section shows how we connect to the recent changes feed using the SSE client library.
Let's run this script as shown below:
python wiki.pyWe'll see the following (truncated) output:
Output
{'$schema': '/mediawiki/recentchange/1.0.0',
'bot': False,
'comment': '[[:File:Storemyr-Fagerbakken landskapsvernområde HVASSER '
'Oslofjorden Norway (Protected coastal forest Recreational area '
'hiking trails) Rituell-kultisk steinstreng sørøst i skogen (small '
'archeological stone string) Vår (spring) 2021-04-24.jpg]] removed '
'from category',
'id': 1923506287,
'meta': {'domain': 'commons.wikimedia.org',
'dt': '2022-05-12T09:57:00Z',
'id': '3800228e-43d8-440d-8034-c68977742653',
'offset': 3855767440,
'partition': 0,
'request_id': '930b17cc-f14a-4656-afa1-d15b79a8f666',
'stream': 'mediawiki.recentchange',
'topic': 'eqiad.mediawiki.recentchange',
'uri': 'https://commons.wikimedia.org/wiki/Category:Iron_Age_in_Norway'},
'namespace': 14,
'parsedcomment': '<a '
'href="/wiki/File:Storemyr-Fagerbakken_landskapsvernomr%C3%A5de_HVASSER_Oslofjorden_Norway_(Protected_coastal_forest_Recreational_area_hiking_trails)_Rituell-kultisk_steinstreng_s%C3%B8r%C3%B8st_i_skogen_(small_archeological_stone_string)_V%C3%A5r_(spring)_2021-04-24.jpg" '
'title="File:Storemyr-Fagerbakken landskapsvernområde '
'HVASSER Oslofjorden Norway (Protected coastal forest '
'Recreational area hiking trails) Rituell-kultisk '
'steinstreng sørøst i skogen (small archeological stone '
'string) Vår (spring) '
'2021-04-24.jpg">File:Storemyr-Fagerbakken '
'landskapsvernområde HVASSER Oslofjorden Norway (Protected '
'coastal forest Recreational area hiking trails) '
'Rituell-kultisk steinstreng sørøst i skogen (small '
'archeological stone string) Vår (spring) 2021-04-24.jpg</a> '
'removed from category',
'server_name': 'commons.wikimedia.org',
'server_script_path': '/w',
'server_url': 'https://commons.wikimedia.org',
'timestamp': 1652349420,
'title': 'Category:Iron Age in Norway',
'type': 'categorize',
'user': 'Krg',
'wiki': 'commonswiki'}
{'$schema': '/mediawiki/recentchange/1.0.0',
'bot': False,
'comment': '[[:File:Storemyr-Fagerbakken landskapsvernområde HVASSER '
'Oslofjorden Norway (Protected coastal forest Recreational area '
'hiking trails) Rituell-kultisk steinstreng sørøst i skogen (small '
'archeological stone string) Vår (spring) 2021-04-24.jpg]] removed '
'from category',
'id': 1923506289,
'meta': {'domain': 'commons.wikimedia.org',
'dt': '2022-05-12T09:57:00Z',
'id': '2b819d20-beca-46a5-8ce3-b2f3b73d2cbe',
'offset': 3855767441,
'partition': 0,
'request_id': '930b17cc-f14a-4656-afa1-d15b79a8f666',
'stream': 'mediawiki.recentchange',
'topic': 'eqiad.mediawiki.recentchange',
'uri': 'https://commons.wikimedia.org/wiki/Category:Cultural_heritage_monuments_in_F%C3%A6rder'},
'namespace': 14,
'parsedcomment': '<a '
'href="/wiki/File:Storemyr-Fagerbakken_landskapsvernomr%C3%A5de_HVASSER_Oslofjorden_Norway_(Protected_coastal_forest_Recreational_area_hiking_trails)_Rituell-kultisk_steinstreng_s%C3%B8r%C3%B8st_i_skogen_(small_archeological_stone_string)_V%C3%A5r_(spring)_2021-04-24.jpg" '
'title="File:Storemyr-Fagerbakken landskapsvernområde '
'HVASSER Oslofjorden Norway (Protected coastal forest '
'Recreational area hiking trails) Rituell-kultisk '
'steinstreng sørøst i skogen (small archeological stone '
'string) Vår (spring) '
'2021-04-24.jpg">File:Storemyr-Fagerbakken '
'landskapsvernområde HVASSER Oslofjorden Norway (Protected '
'coastal forest Recreational area hiking trails) '
'Rituell-kultisk steinstreng sørøst i skogen (small '
'archeological stone string) Vår (spring) 2021-04-24.jpg</a> '
'removed from category',
'server_name': 'commons.wikimedia.org',
'server_script_path': '/w',
'server_url': 'https://commons.wikimedia.org',
'timestamp': 1652349420,
'title': 'Category:Cultural heritage monuments in Færder',
'type': 'categorize',
'user': 'Krg',
'wiki': 'commonswiki'}Ingest recent changes into Kafka
Now we're going to import each of the events into Apache Kafka.
First let's create a Kafka topic called wiki_events with 5 partitions:
docker exec -it kafka-wiki kafka-topics.sh \
--bootstrap-server localhost:9092 \
--create \
--topic wiki_events \
--partitions 5Create a new file called wiki_to_kafka.py and import the following libraries:
import json
import sseclient
import datetime
import requests
import time
from confluent_kafka import Producerwiki_to_kafka.py
Add these functions:
def with_requests(url, headers):
"""Get a streaming response for the given event feed using requests."""
return requests.get(url, stream=True, headers=headers)
def acked(err, msg):
if err is not None:
print("Failed to deliver message: {0}: {1}"
.format(msg.value(), err.str()))
def json_serializer(obj):
if isinstance(obj, (datetime.datetime, datetime.date)):
return obj.isoformat()
raise "Type %s not serializable" % type(obj)wiki_to_kafka.py
And now let's add the code that calls the recent changes API and imports events into the wiki_events topic:
producer = Producer({'bootstrap.servers': 'localhost:9092'})
url = 'https://stream.wikimedia.org/v2/stream/recentchange'
headers = {'Accept': 'text/event-stream'}
response = with_requests(url, headers)
client = sseclient.SSEClient(response)
events_processed = 0
while True:
try:
for event in client.events():
stream = json.loads(event.data)
payload = json.dumps(stream, default=json_serializer, ensure_ascii=False).encode('utf-8')
producer.produce(topic='wiki_events',
key=str(stream['meta']['id']), value=payload, callback=acked)
events_processed += 1
if events_processed % 100 == 0:
print(f"{str(datetime.datetime.now())} Flushing after {events_processed} events")
producer.flush()
except Exception as ex:
print(f"{str(datetime.datetime.now())} Got error:" + str(ex))
response = with_requests(url, headers)
client = sseclient.SSEClient(response)
time.sleep(2)wiki_to_kafka.py
The highlighted parts of this script indicate where events are ingested into Kafka and then flushed to disk.
If we run this script:
python wiki_to_kafka.pyWe'll see a message every time 100 messages are pushed to Kafka, as shown below:
Output
2022-05-12 10:58:34.449326 Flushing after 100 events
2022-05-12 10:58:39.151599 Flushing after 200 events
2022-05-12 10:58:43.399528 Flushing after 300 events
2022-05-12 10:58:47.350277 Flushing after 400 events
2022-05-12 10:58:50.847959 Flushing after 500 events
2022-05-12 10:58:54.768228 Flushing after 600 eventsExplore Kafka
Let's check that the data has made its way into Kafka.
The following command returns the message offset for each partition in the wiki_events topic:
docker exec -it kafka-wiki kafka-run-class.sh kafka.tools.GetOffsetShell \
--broker-list localhost:9092 \
--topic wiki_eventsOutput
wiki_events:0:42
wiki_events:1:61
wiki_events:2:52
wiki_events:3:56
wiki_events:4:58Looks good. We can also stream all the messages in this topic by running the following command:
docker exec -it kafka-wiki kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic wiki_events \
--from-beginningOutput
...
{"$schema": "/mediawiki/recentchange/1.0.0", "meta": {"uri": "https://en.wikipedia.org/wiki/Super_Wings", "request_id": "6f82e64d-220f-41f4-88c3-2e15f03ae504", "id": "c30cd735-1ead-405e-94d1-49fbe7c40411", "dt": "2022-05-12T10:05:36Z", "domain": "en.wikipedia.org", "stream": "mediawiki.recentchange", "topic": "eqiad.mediawiki.recentchange", "partition": 0, "offset": 3855779703}, "type": "log", "namespace": 0, "title": "Super Wings", "comment": "", "timestamp": 1652349936, "user": "2001:448A:50E0:885B:FD1D:2D04:233E:7647", "bot": false, "log_id": 0, "log_type": "abusefilter", "log_action": "hit", "log_params": {"action": "edit", "filter": "550", "actions": "tag", "log": 32575794}, "log_action_comment": "2001:448A:50E0:885B:FD1D:2D04:233E:7647 triggered [[Special:AbuseFilter/550|filter 550]], performing the action \"edit\" on [[Super Wings]]. Actions taken: Tag ([[Special:AbuseLog/32575794|details]])", "server_url": "https://en.wikipedia.org", "server_name": "en.wikipedia.org", "server_script_path": "/w", "wiki": "enwiki", "parsedcomment": ""}
{"$schema": "/mediawiki/recentchange/1.0.0", "meta": {"uri": "https://no.wikipedia.org/wiki/Brukerdiskusjon:Haros", "request_id": "a20c9692-f301-4faf-9373-669bebbffff4", "id": "566ee63e-8e86-4a7e-a1f3-562704306509", "dt": "2022-05-12T10:05:36Z", "domain": "no.wikipedia.org", "stream": "mediawiki.recentchange", "topic": "eqiad.mediawiki.recentchange", "partition": 0, "offset": 3855779714}, "id": 84572581, "type": "edit", "namespace": 3, "title": "Brukerdiskusjon:Haros", "comment": "/* Stor forbokstav / ucfirst */", "timestamp": 1652349936, "user": "Asav", "bot": false, "minor": false, "patrolled": true, "length": {"old": 110378, "new": 110380}, "revision": {"old": 22579494, "new": 22579495}, "server_url": "https://no.wikipedia.org", "server_name": "no.wikipedia.org", "server_script_path": "/w", "wiki": "nowiki", "parsedcomment": "<span dir=\"auto\"><span class=\"autocomment\"><a href=\"/wiki/Brukerdiskusjon:Haros#Stor_forbokstav_/_ucfirst\" title=\"Brukerdiskusjon:Haros\">→Stor forbokstav / ucfirst</a></span></span>"}
{"$schema": "/mediawiki/recentchange/1.0.0", "meta": {"uri": "https://es.wikipedia.org/wiki/Campo_de_la_calle_Industria", "request_id": "d45bd9af-3e2c-4aac-ae8f-e16d3340da76", "id": "7fb3956e-9bd2-4fa5-8659-72b266cdb45b", "dt": "2022-05-12T10:05:35Z", "domain": "es.wikipedia.org", "stream": "mediawiki.recentchange", "topic": "eqiad.mediawiki.recentchange", "partition": 0, "offset": 3855779718}, "id": 266270269, "type": "edit", "namespace": 0, "title": "Campo de la calle Industria", "comment": "/* Historia */", "timestamp": 1652349935, "user": "Raimon will", "bot": false, "minor": false, "length": {"old": 7566, "new": 7566}, "revision": {"old": 143485393, "new": 143485422}, "server_url": "https://es.wikipedia.org", "server_name": "es.wikipedia.org", "server_script_path": "/w", "wiki": "eswiki", "parsedcomment": "<span dir=\"auto\"><span class=\"autocomment\"><a href=\"/wiki/Campo_de_la_calle_Industria#Historia\" title=\"Campo de la calle Industria\">→Historia</a></span></span>"}
^CProcessed a total of 269 messagesConfigure Pinot
Now let's configure Pinot to consume the data from Kafka.
We'll have the following schema:
{
"schemaName": "wikipedia",
"dimensionFieldSpecs": [
{
"name": "id",
"dataType": "STRING"
},
{
"name": "wiki",
"dataType": "STRING"
},
{
"name": "user",
"dataType": "STRING"
},
{
"name": "title",
"dataType": "STRING"
},
{
"name": "comment",
"dataType": "STRING"
},
{
"name": "stream",
"dataType": "STRING"
},
{
"name": "domain",
"dataType": "STRING"
},
{
"name": "topic",
"dataType": "STRING"
},
{
"name": "type",
"dataType": "STRING"
},
{
"name": "uri",
"dataType": "STRING"
},
{
"name": "bot",
"dataType": "BOOLEAN"
},
{
"name": "metaJson",
"dataType": "STRING"
}
],
"dateTimeFieldSpecs": [
{
"name": "ts",
"dataType": "TIMESTAMP",
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}schema.json
And the following table config:
{
"tableName": "wikievents",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "ts",
"schemaName": "wikipedia",
"replication": "1",
"replicasPerPartition": "1"
},
"tableIndexConfig": {
"invertedIndexColumns": [],
"rangeIndexColumns": [],
"autoGeneratedInvertedIndex": false,
"createInvertedIndexDuringSegmentGeneration": false,
"sortedColumn": [],
"bloomFilterColumns": [],
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.topic.name": "wiki_events",
"stream.kafka.broker.list": "kafka-wiki:9093",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"realtime.segment.flush.threshold.rows": "1000",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.segment.size": "100M"
},
"tenants": {
"broker": "DefaultTenant",
"server": "DefaultTenant",
"tagOverrideConfig": {}
},
"noDictionaryColumns": [],
"onHeapDictionaryColumns": [],
"varLengthDictionaryColumns": [],
"enableDefaultStarTree": false,
"enableDynamicStarTreeCreation": false,
"aggregateMetrics": false,
"nullHandlingEnabled": false
},
"metadata": {},
"quota": {},
"routing": {},
"query": {},
"ingestionConfig": {
"transformConfigs": [
{
"columnName": "metaJson",
"transformFunction": "JSONFORMAT(meta)"
},
{
"columnName": "id",
"transformFunction": "JSONPATH(metaJson, '$.id')"
},
{
"columnName": "stream",
"transformFunction": "JSONPATH(metaJson, '$.stream')"
},
{
"columnName": "domain",
"transformFunction": "JSONPATH(metaJson, '$.domain')"
},
{
"columnName": "topic",
"transformFunction": "JSONPATH(metaJson, '$.topic')"
},
{
"columnName": "uri",
"transformFunction": "JSONPATH(metaJson, '$.uri')"
},
{
"columnName": "ts",
"transformFunction": "\"timestamp\" * 1000"
}
]
},
"isDimTable": false
}table.json
The highlighted lines are how we connect Pinot to the Kafka topic that contains the events. Create the schema and table by running the following commnad:
docker exec -it pinot-controller-wiki bin/pinot-admin.sh AddTable \
-tableConfigFile /config/table.json \
-schemaFile /config/schema.json \
-execOnce you've done that, navigate to the Pinot UI (opens in a new tab) and run the following query to check that the data has made its way into Pinot:
select domain, count(*)
from wikievents
group by domain
order by count(*) DESC
limit 10As long as you see some records, everything is working as expected.
Building a Dash Dashboard
Now let's write some more queries against Pinot and display the results in Dash.
First, install the following libraries:
pip install dash pinotdb plotly pandasCreate a file called dashboard.py and import libraries and write a header for the page:
import pandas as pd
from dash import Dash, html, dcc
import plotly.graph_objects as go
from pinotdb import connect
import plotly.express as px
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = Dash(__name__, external_stylesheets=external_stylesheets)
app.title = "Wiki Recent Changes Dashboard"app.py
Connect to Pinot and write a query that returns recent changes, along with the users who made the changes, and domains where they were made:
conn = connect(host='localhost', port=8099, path='/query/sql', scheme='http')
query = """select
count(*) FILTER(WHERE ts > ago('PT1M')) AS events1Min,
count(*) FILTER(WHERE ts <= ago('PT1M') AND ts > ago('PT2M')) AS events1Min2Min,
distinctcount(user) FILTER(WHERE ts > ago('PT1M')) AS users1Min,
distinctcount(user) FILTER(WHERE ts <= ago('PT1M') AND ts > ago('PT2M')) AS users1Min2Min,
distinctcount(domain) FILTER(WHERE ts > ago('PT1M')) AS domains1Min,
distinctcount(domain) FILTER(WHERE ts <= ago('PT1M') AND ts > ago('PT2M')) AS domains1Min2Min
from wikievents
where ts > ago('PT2M')
limit 1
"""
curs = conn.cursor()
curs.execute(query)
df_summary = pd.DataFrame(curs, columns=[item[0] for item in curs.description])app.py
The highlighted part of the query shows how to count the number of events from the last minute and the minute before that. We then do a similar thing to count the number of unique users and domains.
Metrics
Now let's create some metrics based on that data.
First, let's create a couple of helper functions for creating these metrics:
from dash import html, dash_table
import plotly.graph_objects as go
def add_delta_trace(fig, title, value, last_value, row, column):
fig.add_trace(go.Indicator(
mode = "number+delta",
title= {'text': title},
value = value,
delta = {'reference': last_value, 'relative': True},
domain = {'row': row, 'column': column})
)
def add_trace(fig, title, value, row, column):
fig.add_trace(go.Indicator(
mode = "number",
title= {'text': title},
value = value,
domain = {'row': row, 'column': column})
)dash_utils.py
And now let's add the following import to app.py:
from dash_utils import add_delta_trace, add_traceapp.py
And the following code at the end of the file:
fig = go.Figure(layout=go.Layout(height=300))
if df_summary["events1Min"][0] > 0:
if df_summary["events1Min"][0] > 0:
add_delta_trace(fig, "Changes", df_summary["events1Min"][0], df_summary["events1Min2Min"][0], 0, 0)
add_delta_trace(fig, "Users", df_summary["users1Min"][0], df_summary["users1Min2Min"][0], 0, 1)
add_delta_trace(fig, "Domain", df_summary["domains1Min"][0], df_summary["domains1Min2Min"][0], 0, 2)
else:
add_trace(fig, "Changes", df_summary["events1Min"][0], 0, 0)
add_trace(fig, "Users", df_summary["users1Min2Min"][0], 0, 1)
add_trace(fig, "Domains", df_summary["domains1Min2Min"][0], 0, 2)
fig.update_layout(grid = {"rows": 1, "columns": 3, 'pattern': "independent"},)
else:
fig.update_layout(annotations = [{"text": "No events found", "xref": "paper", "yref": "paper", "showarrow": False, "font": {"size": 28}}])
app.layout = html.Div([
html.H1("Wiki Recent Changes Dashboard", style={'text-align': 'center'}),
html.Div(id='content', children=[
dcc.Graph(figure=fig)
])
])
if __name__ == '__main__':
app.run_server(debug=True) app.py
Go back to the terminal and run the following command:
python dashboard.pyNavigate to localhost:8501 (opens in a new tab) to see the Dash app. You should see something like the following:
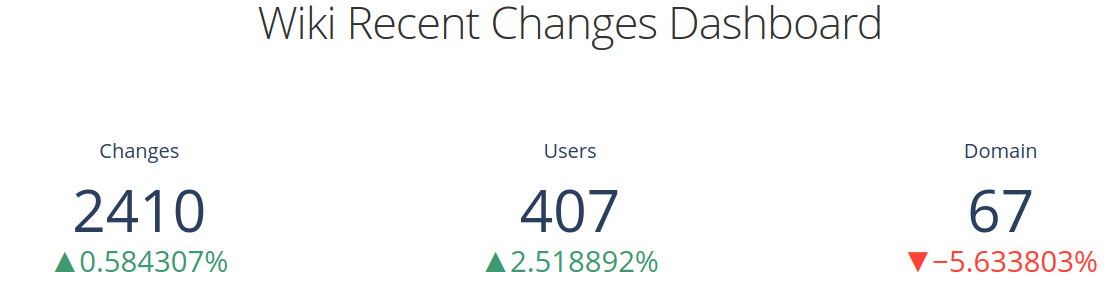 Dash Metrics
Dash Metrics
Changes per minute
Next, let's add a line chart that shows the number of changes being done to Wikimedia per minute.
Update app.py as follows:
query = """
select ToDateTime(DATETRUNC('minute', ts), 'yyyy-MM-dd hh:mm:ss') AS dateMin, count(*) AS changes,
distinctcount(user) AS users,
distinctcount(domain) AS domains
from wikievents
where ts > ago('PT2M')
group by dateMin
order by dateMin desc
LIMIT 30
"""
curs.execute(query)
df_ts = pd.DataFrame(curs, columns=[item[0] for item in curs.description])
df_ts_melt = pd.melt(df_ts, id_vars=['dateMin'], value_vars=['changes', 'users', 'domains'])
line_chart = px.line(df_ts_melt, x='dateMin', y="value", color='variable', color_discrete_sequence =['blue', 'red', 'green'])
line_chart['layout'].update(margin=dict(l=0,r=0,b=0,t=40), title="Changes/Users/Domains per minute")
line_chart.update_yaxes(range=[0, df_ts["changes"].max() * 1.1])
app.layout = html.Div([
html.H1("Wiki Recent Changes Dashboard", style={'text-align': 'center'}),
html.Div(id='content', children=[
dcc.Graph(figure=fig),
dcc.Graph(figure=line_chart),
])
])app.py
Go back to the web browser and you should see something like this:
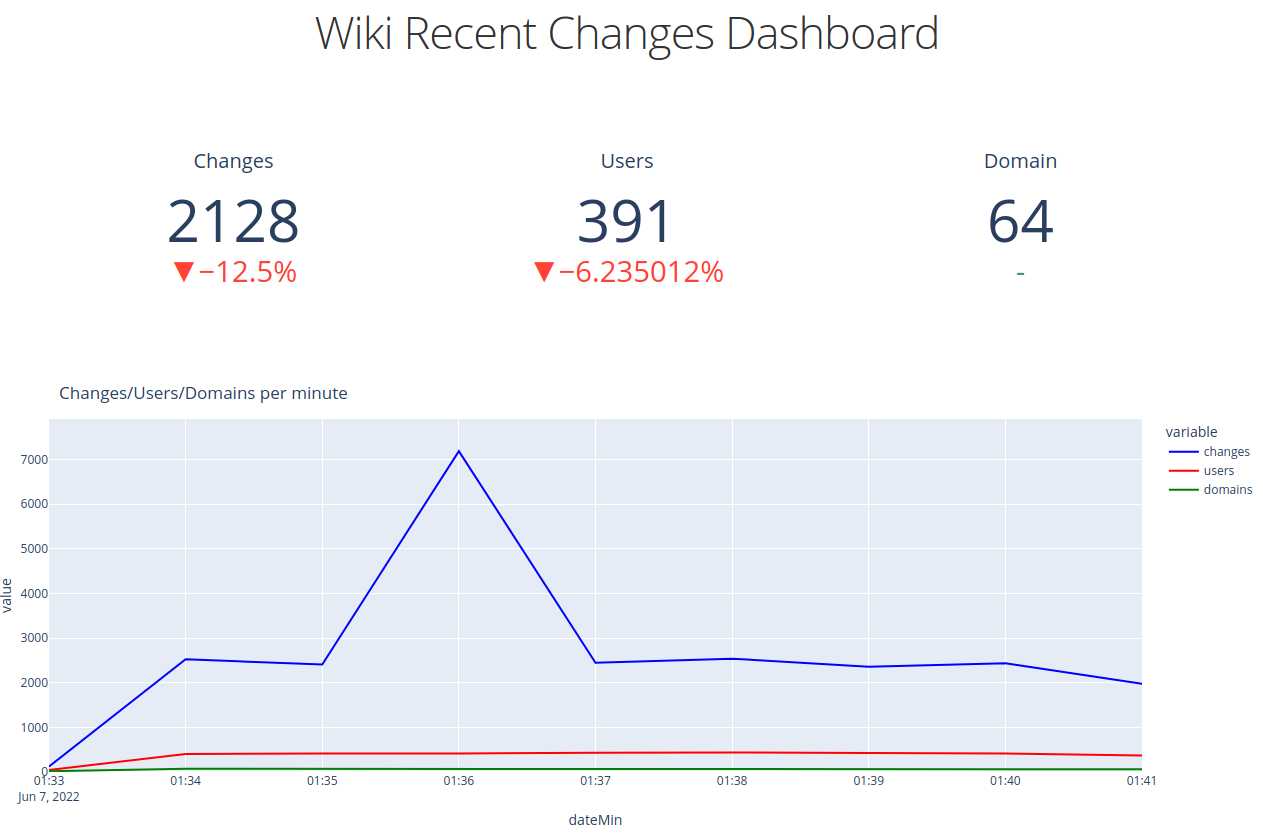 Dash Time Series
Dash Time Series
Auto Refresh
At the moment we need to refresh our web browser to update the metrics and line chart, but it would be much better if that happened automatically. Let's now add auto refresh functionality.
This will require some restructuring of our application so that each component is rendered from a function annotated with a callback that causes the function to be called on an interval.
The app layout now looks like this:
app.layout = html.Div([
html.H1("Wiki Recent Changes Dashboard", style={'text-align': 'center'}),
html.Div(id='latest-timestamp', style={"padding": "5px 0", "text-align": "center"}),
dcc.Interval(
id='interval-component',
interval=1 * 1000,
n_intervals=0
),
html.Div(id='content', children=[
dcc.Graph(id="indicators"),
dcc.Graph(id="time-series"),
])
])app.py
interval-componentis configured to fire a callback every 1,000 milliseconds.latest-timestampis a container that will contain the latest timestamp.indicatorswill contain indicators with the latest counts of users, domains, and changes.time-serieswill contain the time series line chart.
The timestamp is refreshed by the following callback function:
@app.callback(
Output(component_id='latest-timestamp', component_property='children'),
Input('interval-component', 'n_intervals'))
def timestamp(n):
return html.Span(f"Last updated: {datetime.datetime.now()}")app.py
The indicators are refreshed by this function:
@app.callback(Output(component_id='indicators', component_property='figure'),
Input('interval-component', 'n_intervals'))
def indicators(n):
query = """
select count(*) FILTER(WHERE ts > ago('PT1M')) AS events1Min,
count(*) FILTER(WHERE ts <= ago('PT1M') AND ts > ago('PT2M')) AS events1Min2Min,
distinctcount(user) FILTER(WHERE ts > ago('PT1M')) AS users1Min,
distinctcount(user) FILTER(WHERE ts <= ago('PT1M') AND ts > ago('PT2M')) AS users1Min2Min,
distinctcount(domain) FILTER(WHERE ts > ago('PT1M')) AS domains1Min,
distinctcount(domain) FILTER(WHERE ts <= ago('PT1M') AND ts > ago('PT2M')) AS domains1Min2Min
from wikievents
where ts > ago('PT2M')
limit 1
"""
curs = connection.cursor()
curs.execute(query)
df_summary = pd.DataFrame(curs, columns=[item[0] for item in curs.description])
curs.close()
fig = go.Figure(layout=go.Layout(height=300))
if df_summary["events1Min"][0] > 0:
if df_summary["events1Min"][0] > 0:
add_delta_trace(fig, "Changes", df_summary["events1Min"][0], df_summary["events1Min2Min"][0], 0, 0)
add_delta_trace(fig, "Users", df_summary["users1Min"][0], df_summary["users1Min2Min"][0], 0, 1)
add_delta_trace(fig, "Domain", df_summary["domains1Min"][0], df_summary["domains1Min2Min"][0], 0, 2)
else:
add_trace(fig, "Changes", df_summary["events1Min"][0], 0, 0)
add_trace(fig, "Users", df_summary["users1Min2Min"][0], 0, 1)
add_trace(fig, "Domains", df_summary["domains1Min2Min"][0], 0, 2)
fig.update_layout(grid = {"rows": 1, "columns": 3, 'pattern': "independent"},)
else:
fig.update_layout(annotations = [{"text": "No events found", "xref": "paper", "yref": "paper", "showarrow": False, "font": {"size": 28}}])
return figapp.py
And finally, the following function refreshes the line chart:
@app.callback(Output(component_id='time-series', component_property='figure'),
Input('interval-component', 'n_intervals'))
def time_series(n):
query = """
select ToDateTime(DATETRUNC('minute', ts), 'yyyy-MM-dd hh:mm:ss') AS dateMin, count(*) AS changes,
distinctcount(user) AS users,
distinctcount(domain) AS domains
from wikievents
where ts > ago('PT1H')
group by dateMin
order by dateMin desc
LIMIT 30
"""
curs = connection.cursor()
curs.execute(query)
df_ts = pd.DataFrame(curs, columns=[item[0] for item in curs.description])
curs.close()
df_ts_melt = pd.melt(df_ts, id_vars=['dateMin'], value_vars=['changes', 'users', 'domains'])
line_chart = px.line(df_ts_melt, x='dateMin', y="value", color='variable', color_discrete_sequence =['blue', 'red', 'green'])
line_chart['layout'].update(margin=dict(l=0,r=0,b=0,t=40), title="Changes/Users/Domains per minute")
line_chart.update_yaxes(range=[0, df_ts["changes"].max() * 1.1])
return line_chartapp.py
If we navigate back to our web browser, we'll see the following:
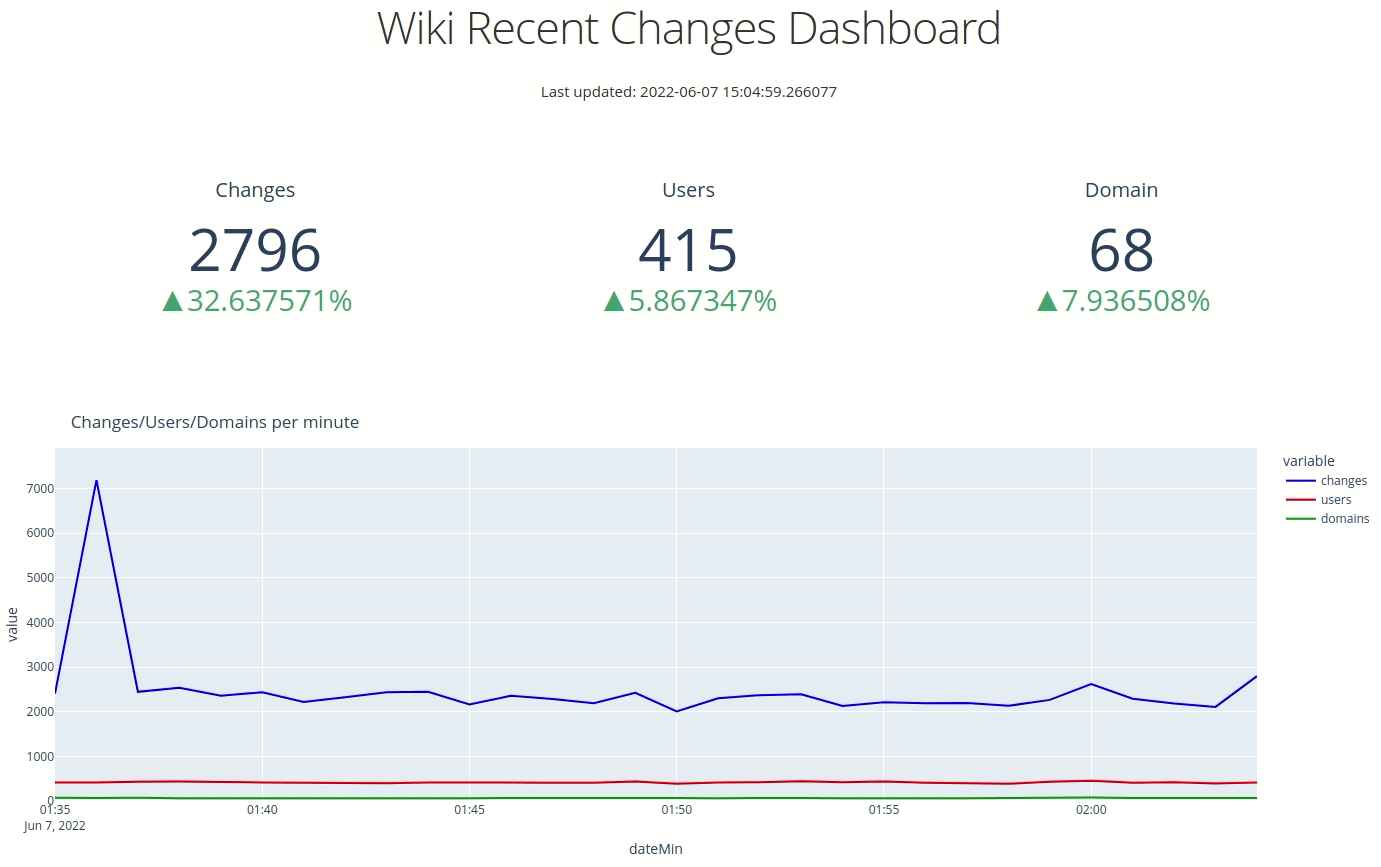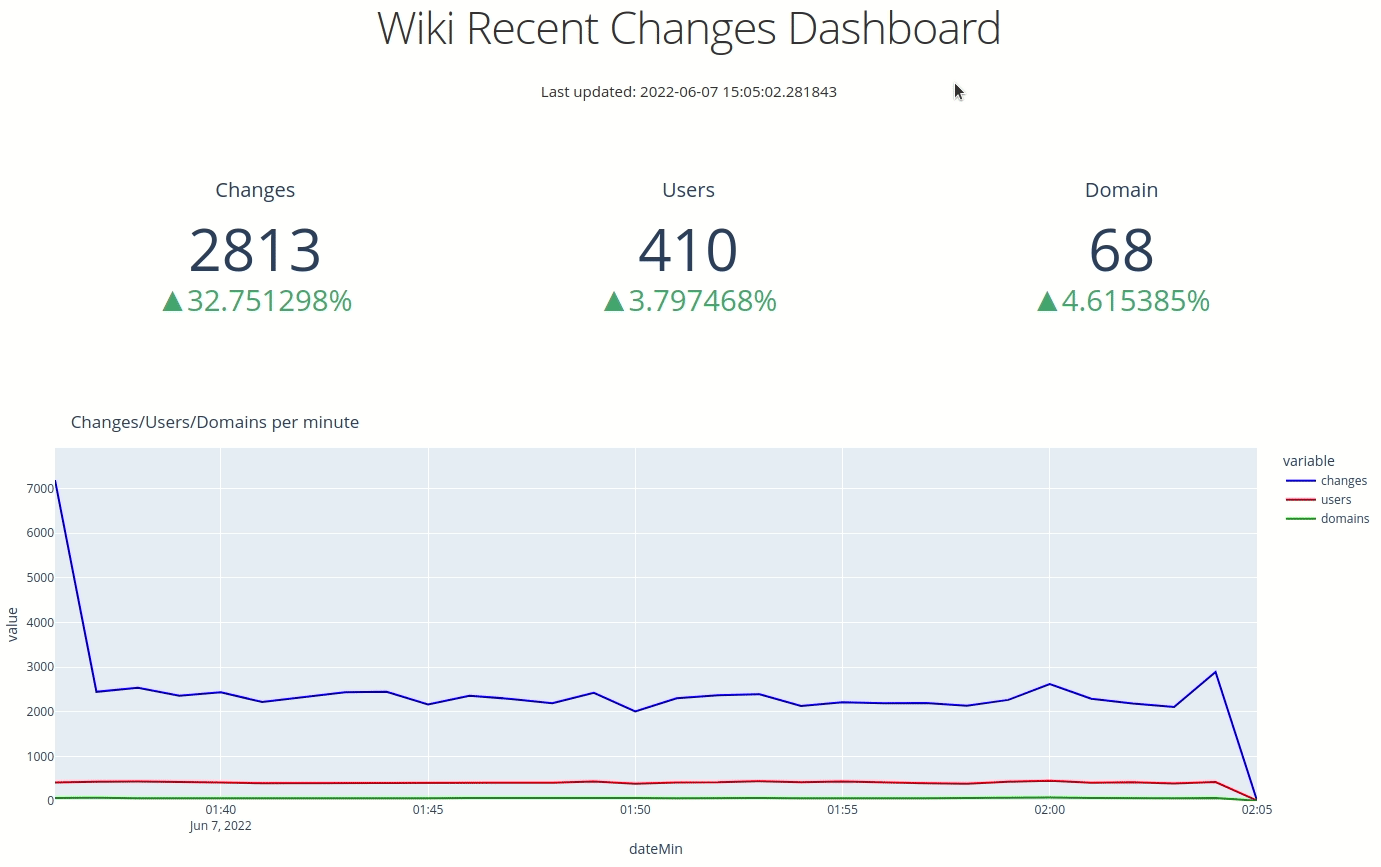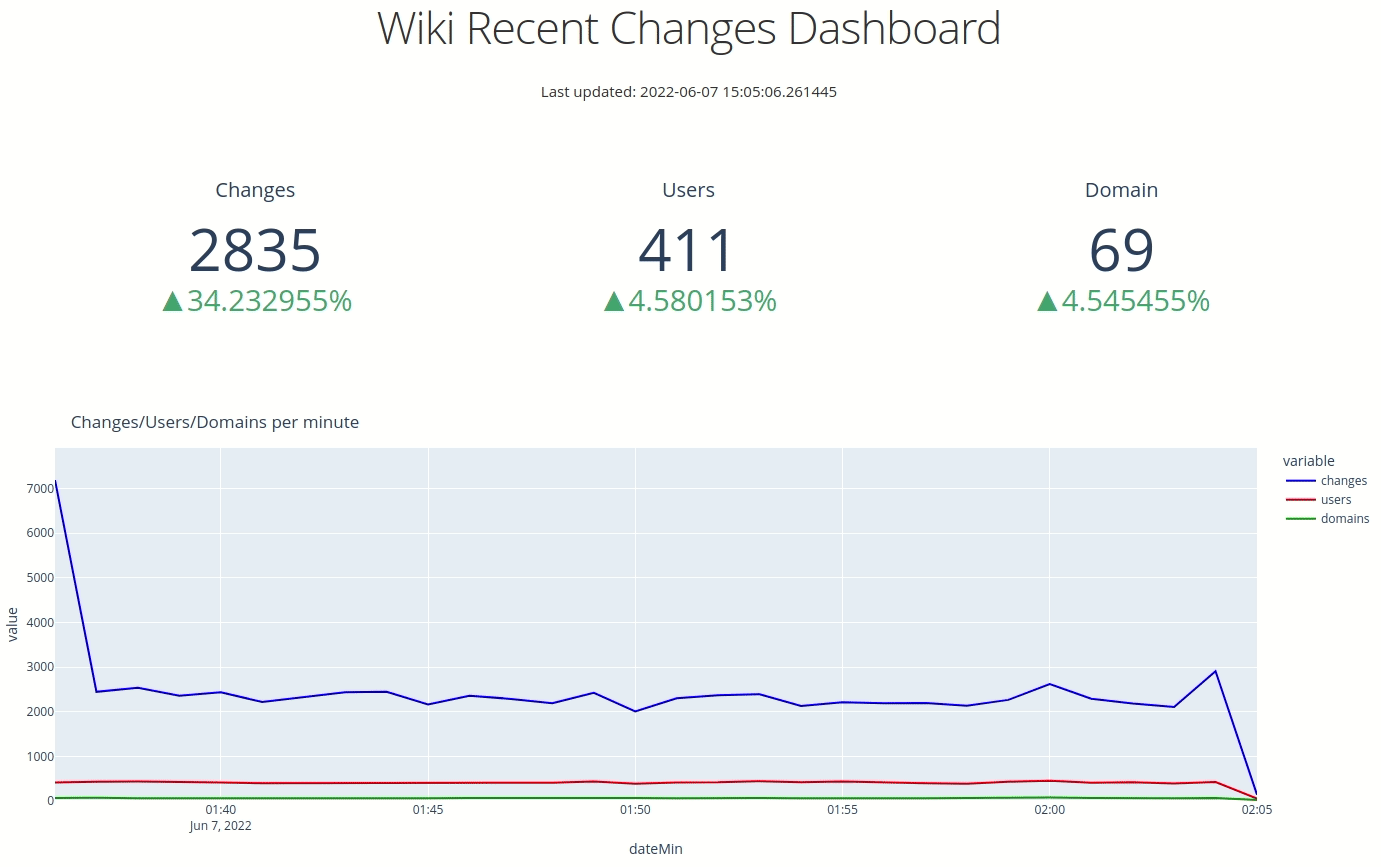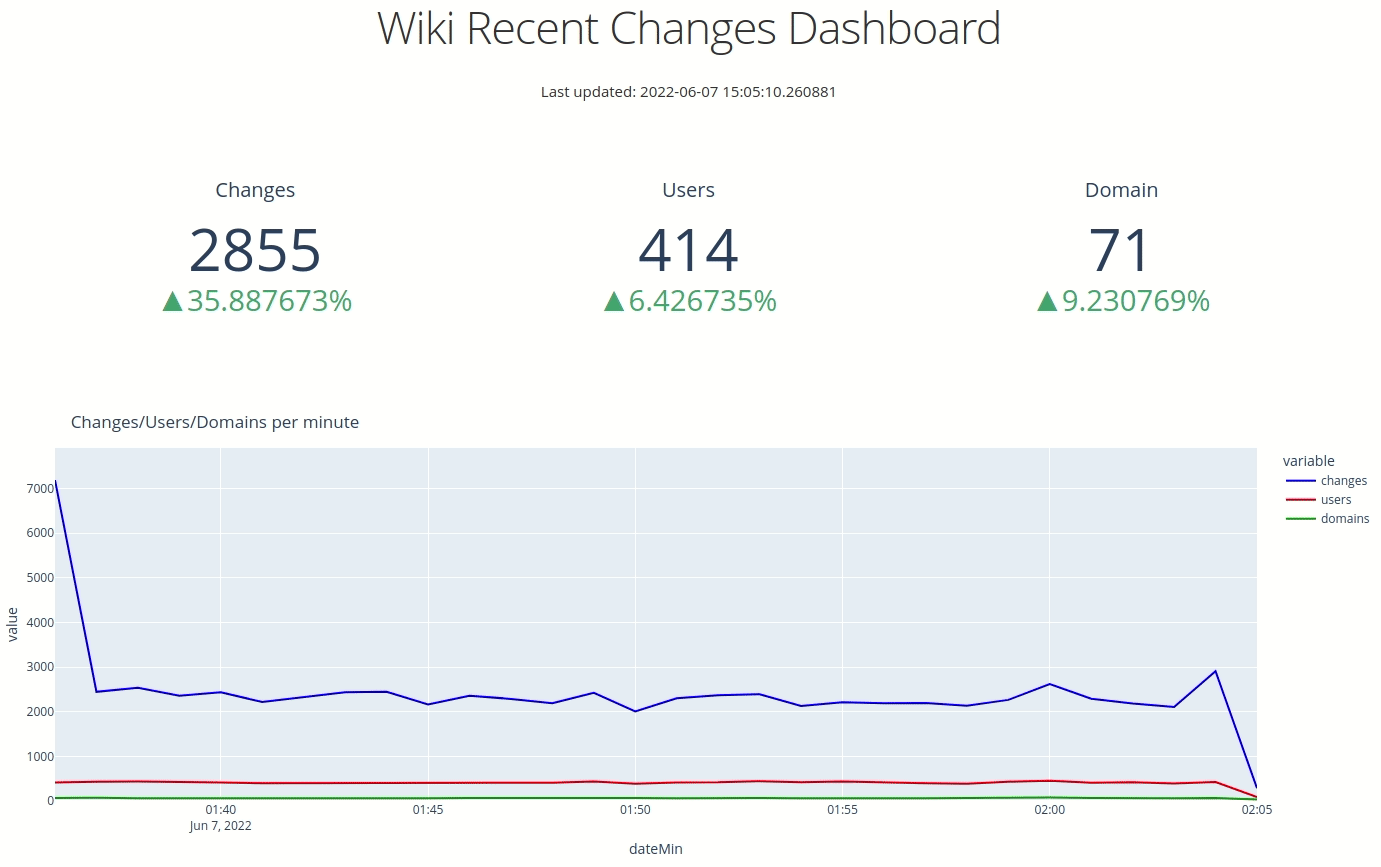 Dash Auto Refresh
Dash Auto Refresh
The full script used in this example is shown below:
import pandas as pd
from dash import Dash, html, dash_table, dcc, Input, Output
import plotly.graph_objects as go
from pinotdb import connect
from dash_utils import add_delta_trace, add_trace
import plotly.express as px
import datetime
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = Dash(__name__, external_stylesheets=external_stylesheets)
app.title = "Wiki Recent Changes Dashboard"
connection = connect(host="localhost", port="8099", path="/query/sql", scheme=( "http"))
@app.callback(Output(component_id='indicators', component_property='figure'),
Input('interval-component', 'n_intervals'))
def indicators(n):
query = """
select count(*) FILTER(WHERE ts > ago('PT1M')) AS events1Min,
count(*) FILTER(WHERE ts <= ago('PT1M') AND ts > ago('PT2M')) AS events1Min2Min,
distinctcount(user) FILTER(WHERE ts > ago('PT1M')) AS users1Min,
distinctcount(user) FILTER(WHERE ts <= ago('PT1M') AND ts > ago('PT2M')) AS users1Min2Min,
distinctcount(domain) FILTER(WHERE ts > ago('PT1M')) AS domains1Min,
distinctcount(domain) FILTER(WHERE ts <= ago('PT1M') AND ts > ago('PT2M')) AS domains1Min2Min
from wikievents
where ts > ago('PT2M')
limit 1
"""
curs = connection.cursor()
curs.execute(query)
df_summary = pd.DataFrame(curs, columns=[item[0] for item in curs.description])
curs.close()
fig = go.Figure(layout=go.Layout(height=300))
if df_summary["events1Min"][0] > 0:
if df_summary["events1Min"][0] > 0:
add_delta_trace(fig, "Changes", df_summary["events1Min"][0], df_summary["events1Min2Min"][0], 0, 0)
add_delta_trace(fig, "Users", df_summary["users1Min"][0], df_summary["users1Min2Min"][0], 0, 1)
add_delta_trace(fig, "Domain", df_summary["domains1Min"][0], df_summary["domains1Min2Min"][0], 0, 2)
else:
add_trace(fig, "Changes", df_summary["events1Min"][0], 0, 0)
add_trace(fig, "Users", df_summary["users1Min2Min"][0], 0, 1)
add_trace(fig, "Domains", df_summary["domains1Min2Min"][0], 0, 2)
fig.update_layout(grid = {"rows": 1, "columns": 3, 'pattern': "independent"},)
else:
fig.update_layout(annotations = [{"text": "No events found", "xref": "paper", "yref": "paper", "showarrow": False, "font": {"size": 28}}])
return fig
@app.callback(Output(component_id='time-series', component_property='figure'),
Input('interval-component', 'n_intervals'))
def time_series(n):
query = """
select ToDateTime(DATETRUNC('minute', ts), 'yyyy-MM-dd hh:mm:ss') AS dateMin, count(*) AS changes,
distinctcount(user) AS users,
distinctcount(domain) AS domains
from wikievents
where ts > ago('PT1H')
group by dateMin
order by dateMin desc
LIMIT 30
"""
curs = connection.cursor()
curs.execute(query)
df_ts = pd.DataFrame(curs, columns=[item[0] for item in curs.description])
curs.close()
df_ts_melt = pd.melt(df_ts, id_vars=['dateMin'], value_vars=['changes', 'users', 'domains'])
line_chart = px.line(df_ts_melt, x='dateMin', y="value", color='variable', color_discrete_sequence =['blue', 'red', 'green'])
line_chart['layout'].update(margin=dict(l=0,r=0,b=0,t=40), title="Changes/Users/Domains per minute")
line_chart.update_yaxes(range=[0, df_ts["changes"].max() * 1.1])
return line_chart
@app.callback(
Output(component_id='latest-timestamp', component_property='children'),
Input('interval-component', 'n_intervals'))
def timestamp(n):
return html.Span(f"Last updated: {datetime.datetime.now()}")
app.layout = html.Div([
html.H1("Wiki Recent Changes Dashboard", style={'text-align': 'center'}),
html.Div(id='latest-timestamp', style={"padding": "5px 0", "text-align": "center"}),
dcc.Interval(
id='interval-component',
interval=1 * 1000,
n_intervals=0
),
html.Div(id='content', children=[
dcc.Graph(id="indicators"),
dcc.Graph(id="time-series"),
])
])
if __name__ == '__main__':
app.run_server(debug=True)dashboard.py
Summary
In this guide we've learnt how to publish data into Kafka from Wikimedia's event stream, ingest it from there into Pinot, and finally make sense of the data using SQL queries run from Dash.