Real-Time Data Ingestion
When ingesting data from data streaming platforms like Apache Kafka, Pinot needs to monitor the offset that has been read from topic partitions and store it somewhere that's accessible to other servers. Pinot uses Apache Helix (opens in a new tab) to manage this process and the data is stored in Apache Zookeeper.
If you're interested in learning more about the way that the data consumed from these partitions is stored in Pinot, watch the video below in which Neha Pawar gives a detailed explanation.
Neha Pawar explains segment assignment in real-time tables
Why does Pinot not use Kafka consumer groups?
Many applications that consume data from Kafka use Kafka consumer groups to manage this process and it's reasonable to ask why Pinot doesn't do this as well.
In a talk given at Kafka Summit 2020 (opens in a new tab), Neha Pawar explains why Kafka consumer groups aren't used.
In an initial implementation of the real-time ingestion feature, Pinot did in fact use consumer groups to manage offsets and checkpoints across multiple Kafka consumers. We started with one consumer group per server, but this led to storage overhead and didn't have fault tolerance or scalability.
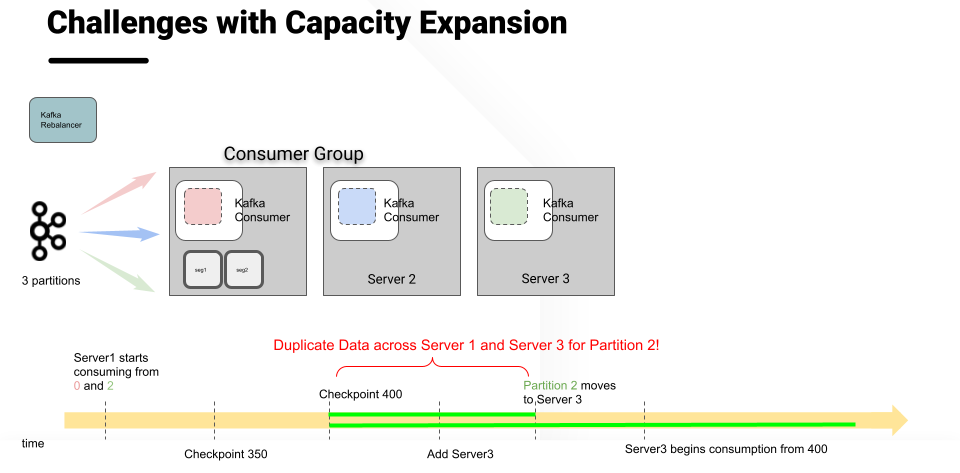 Limitations of one consumer group per server
Limitations of one consumer group per server
Version 2 therefore ran multiple consumer groups for the same topic. This solved the issues with fault tolerance and scalability, but it had its own difficulties. Since Kafka maintains offset per consumer group, achieving data consistency across multiple consumer groups was not possible.
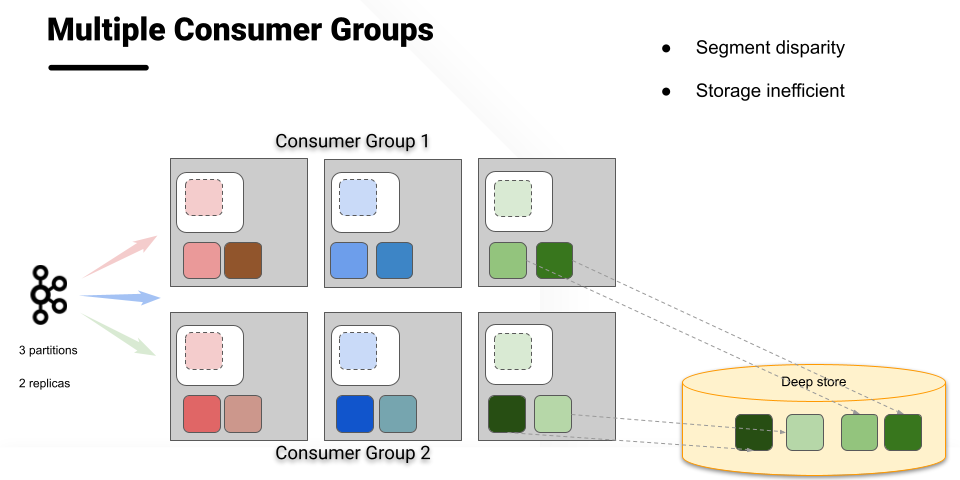 Limitations of multiple consumer groups - data consistency
Limitations of multiple consumer groups - data consistency
In addition, a failure of a single node in a consumer group meant that the entire consumer group would be unavailable for query processing. Restarting that failed node required delicate manual operations to make sure that data was only consumed once, which resulted in management overhead and inefficient hardware utilization.
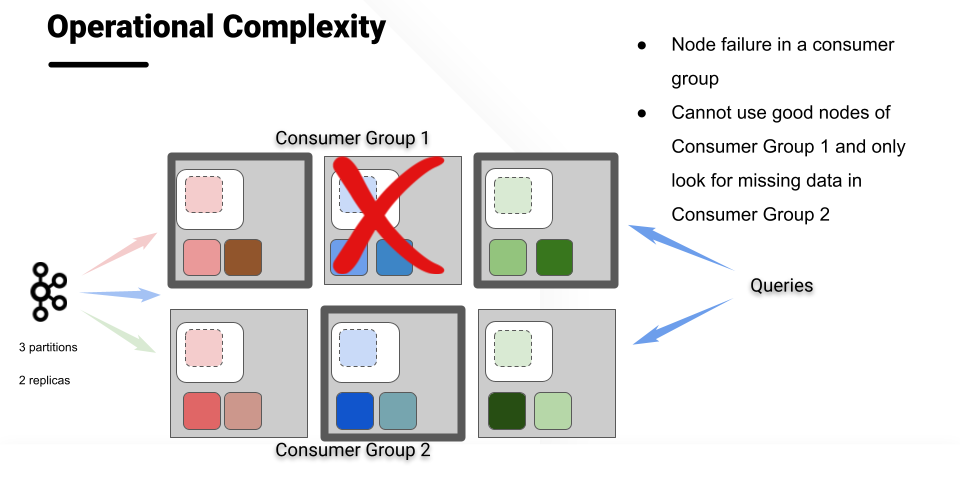 Limitations of multiple consumer groups - servers unavailable for queries
Limitations of multiple consumer groups - servers unavailable for queries
The Pinot team therefore redesigned the real-time consumption in Pinot to maintain consistent offset across multiple consumer groups. The solution takes inspiration from the Kafka consumer group implementation, but also guarantees consistent data across all replicas. The design also enabled us to copy data from another consumer group during node addition, node failure, or increasing the replication group.
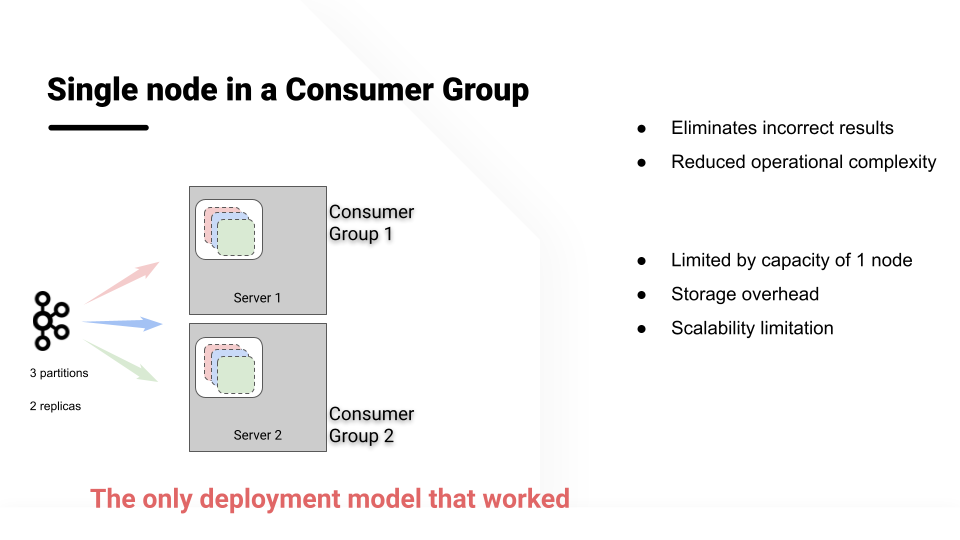 The solution: single node in a consumer group
The solution: single node in a consumer group
If you want to learn about this in more detail, you can watch Neha's talk (opens in a new tab).